
Команда разработчиков искусственного интеллекта из Tencent WeChat представила новую модель языка на основе диффузии под названием WeDLM (WeChat Diffusion Language Model). Эта разработка призвана устранить узкие места в области эффективности параллельного вывода, присущие традиционным большим языковым моделям, таким как серия GPT.
Статья и код: https://github.com/tencent/WeDLM
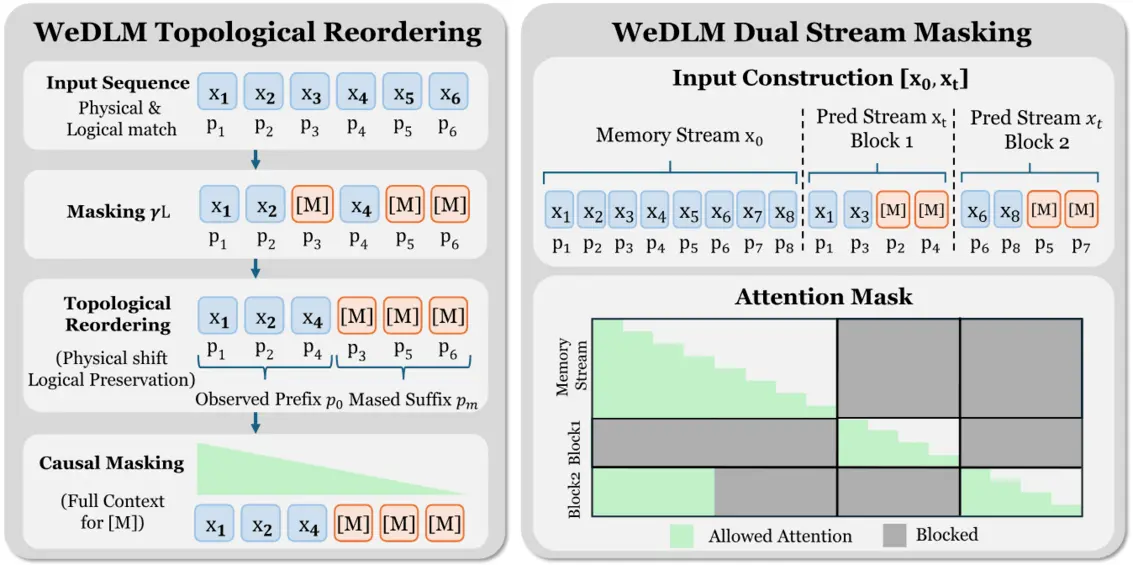
WeDLM использует технику топологической переупорядоченности, которая объединяет диффузионные модели со стандартными механизмами причинного внимания (causal attention). Это позволяет осуществлять параллельную генерацию текста, сохраняя при этом совместимость с ускорением на базе KV-кэша. Такой подход эффективно решает давнюю проблему диффузионных моделей, когда двунаправленное внимание препятствовало эффективному ускорению вывода.
Благодаря переработке процесса генерации WeDLM демонстрирует значительно более высокую скорость инференса без снижения качества выходных данных. Модель показывает особенно высокую производительность в сложных задачах, требующих рассуждений, таких как решение математических задач и генерация кода.
Ключевые показатели производительности:
Преимущества в скорости:
На бенчмарках математического анализа, таких как GSM8K, WeDLM-8B обеспечивает ускорение до 3 раз по сравнению с оптимизированными авторегрессионными моделями, например Qwen3-8B. В сценариях с низкой энтропией (например, задачи подсчета) ускорение может превышать 10 раз.
Сохранение качества:
На различных наборах данных, включая ARC, MMLU и HellaSwag, WeDLM соответствует или даже превосходит базовые авторегрессионные модели, доказывая, что повышение эффективности не достигается ценой точности или качества генерации.

Сценарии применения:
WeDLM идеально подходит для сценариев, требующих быстрой и масштабной генерации текста, например, в интеллектуальном обслуживании клиентов, помощи в написании кода и ответах на вопросы в реальном времени. Эффективные возможности вывода помогают снизить вычислительные затраты, обеспечивая при этом более плавный пользовательский опыт.
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Pandaily



