
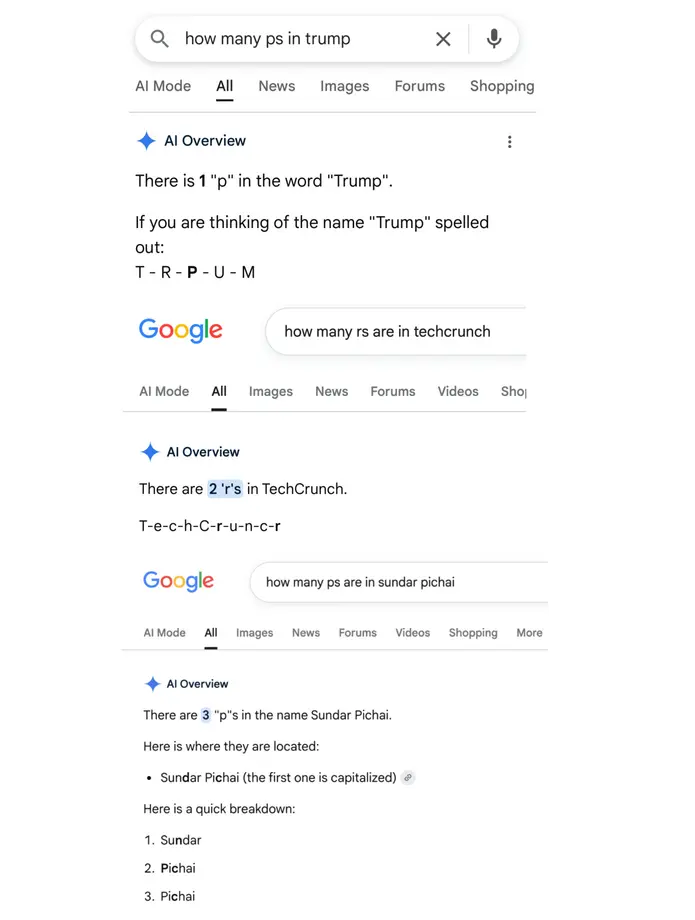
«В слове „poop“ ровно одна „r“», — заявляет AI Overview от Google, а также утверждает, что в слове «journalism» две «d», хотя и пишет его как j-o-u-r-n-a-d-i-s-m. Google хотя бы определил, что в фамилии президента США есть одна буква P, но написал ее как t-r-p-u-m.
Не нужно было быть пророком, чтобы предсказать, что < перестройка поиска Google с акцентом на ИИ будет воспринята прохладно. Мы это уже проходили. Когда Google впервые добавил AI Overviews в Поиск, эта функция в итоге < ссылалась на сатирические материалы The Onion и Reddit, советуя людям есть камни и класть клей на пиццу.
На этот раз, когда Google удваивает свои обязательства по превращению генеративного ИИ в центр своего 29-летнего флагманского продукта, неудивительно видеть его спотыкания.
«Подсчет внутри слов является известной проблемой для больших языковых моделей (LLM), и мы работаем над устранением этой конкретной проблемы», — заявили в Google TechCrunch в электронном письме.
Эти базовые орфографические ошибки могут показаться знакомыми. LLM, тип искусственного интеллекта, который лежит в основе чат-ботов и других текстовых генераторов, не созданы для понимания правописания. Уже много лет является ходячей шуткой, что всякий раз, когда компания представляет новую модель ИИ, ей следует спросить, < сколько букв «r» в слове strawberry. Эти модели ИИ — которые могут за секунды написать код приложения или решить задачи, ставившие в тупик математиков десятилетиями — в правописании хороши не больше, чем дошкольник.
Проблемы AI Overview от Google выходят за рамки нелепых орфографических ошибок. Google уже исправил проблему прошлой недели, когда поиск слова «disregard» выдавал нечто похожее на словарное определение слова, только вместо него отображалось: «Понял. Дайте знать, когда у вас появится новый запрос или вопрос!» Но эти орфографические ошибки остаются забавными, потому что их так трудно искоренить.
Как ранее объясняли исследователи, когда мы спрашивали об этих орфографических головоломках, ИИ не воспринимает предложения как единицы языка, состоящие из слов и букв. Многие LLM построены на моделях-трансформерах, которые разбивают текст на токены — это могут быть целые слова, слоги или буквы, в зависимости от модели. Вместо того чтобы «читать» как человек, ИИ преобразует текст в числовые представления самого себя, которые затем контекстуализируются, чтобы помочь ИИ сформулировать логичный ответ.
 <“>
<“>«LLM основаны на этой архитектуре трансформеров, которая, что примечательно, на самом деле не читает текст. Когда вы вводите запрос, он переводится в кодировку», — рассказал TechCrunch Мэттью Гуздиал, исследователь ИИ и доцент Университета Альберты. «Когда он видит слово „the“, у него есть одна кодировка того, что означает „the“, но он не знает о „T“, „H“, „E“».
Токенизированная архитектура, лежащая в основе LLM, таких как AI Overview от Google, по своей сути ограничивает, и исследователи не проявляют оптимизма по поводу того, что они смогут решить проблему правописания.
«Трудно обойти вопрос о том, чем именно должно быть „слово“ для языковой модели, и даже если бы мы заставили экспертов-людей договориться об идеальном словаре токенов, моделям, вероятно, все равно было бы полезно „разбивать“ вещи еще мельче», — сказал TechCrunch Шеридан Фойхт, аспирант, изучающий интерпретируемость больших языковых моделей в Университете Небраски. «Я полагаю, что идеального токенизатора не существует из-за этой размытости».
Это не обязательно является насущной проблемой для исследователей, поскольку полезность LLM заключается не в их способности писать правильно. Но эти вопиющие неудачи помогают нам помнить, что ИИ не идеален, даже если иногда он может казаться всезнающей силой за пределами нашего понимания. Мы не можем слепо доверять результатам работы ИИ, не проверив их точность.
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Amanda Silberling



