
Компания DeepSeek в сотрудничестве с Пекинским университетом опубликовала новую научную статью, представляющую и открывающую исходный код «Энграмма» (Engram) — условного модуля памяти, разработанного для устранения нехватки эффективных механизмов извлечения знаний в современных больших языковых моделях. Среди соавторов статьи — основатель DeepSeek Лян Вэньфэн.
Исследование предлагает условную память как новое измерение моделирования, которое дополняет парадигму условных вычислений моделей «Смесь экспертов» (Mixture-of-Experts, MoE). Авторы утверждают, что традиционные архитектуры Трансформера неэффективно имитируют извлечение знаний посредством вычислений.
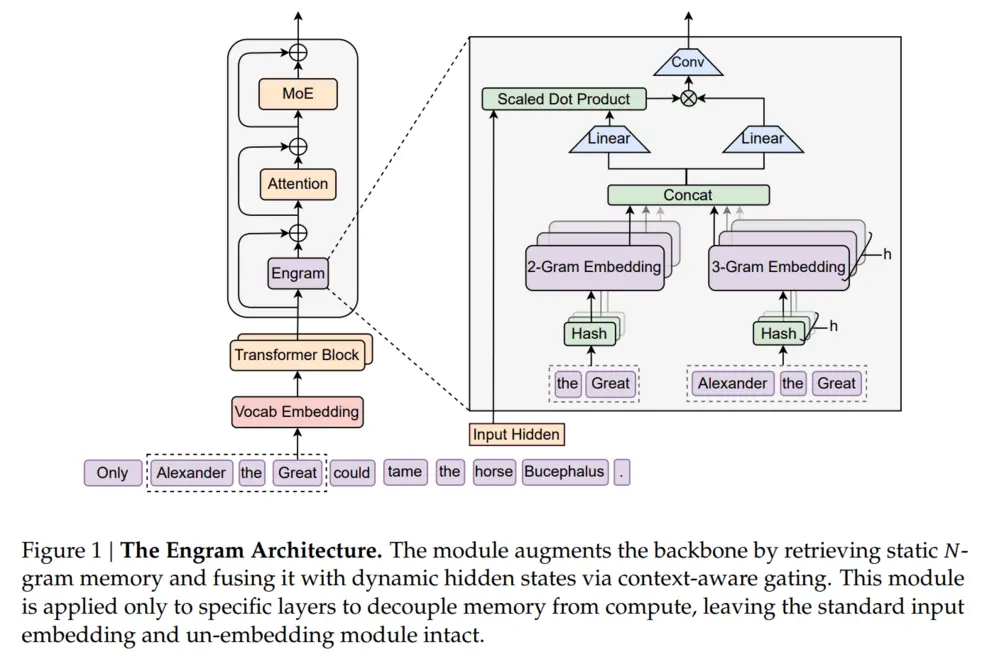
«Энграмм» переосмысливает классические N-граммные встраивания, обеспечивая поиск знаний со сложностью O(1) за счёт отделения хранения статических знаний от динамических вычислений. Он извлекает релевантные статические встраивания посредством хеширования и динамически корректирует их с использованием контекстно-зависимого управления (gating).
Эксперименты выявили U-образное оптимальное распределение между экспертами MoE и памятью «Энграмма» при фиксированных бюджетах параметров и вычислительных ресурсов. Выделение 20–25% разреженных параметров на «Энграмм» даёт наилучшую производительность. В масштабе 27 миллиардов параметров модели с использованием «Энграмма» значительно превосходят чистые эталонные модели MoE при одинаковом количестве параметров и FLOPs.
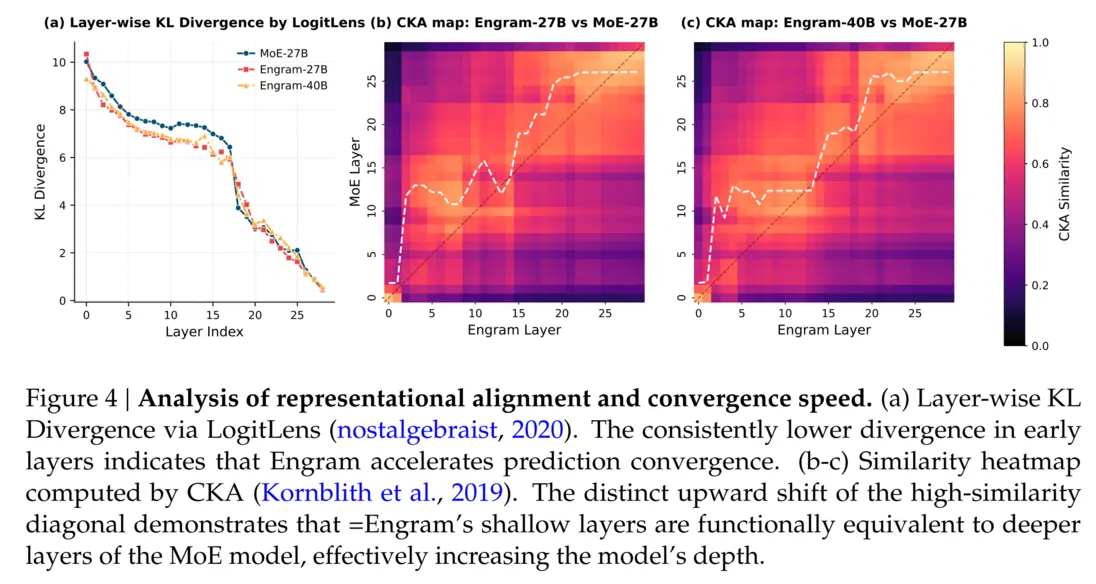
Примечательно, что «Энграмм» демонстрирует прирост не только в задачах, требующих обширных знаний (например, +3.0 по MMLU, +4.0 по CMMLU), но и в общем рассуждении (+5.0 по BBH) и кодовом/математическом рассуждении (+3.0 по HumanEval). Анализ показывает, что «Энграмм» снимает с ранних слоев задачу реконструкции статических знаний, эффективно углубляя способность сети к рассуждению и освобождая механизмы внимания для глобального моделирования. Это приводит к существенному улучшению извлечения информации в длинном контексте, например, повышая точность Multi-Query NIAH с 84,2% до 97,0%.
На системном уровне детерминированное адресование «Энграмма» позволяет масштабировать ёмкость памяти посредством параллелизма моделей во время обучения, одновременно обеспечивая асинхронную предварительную выборку встраиваний через PCIe во время инференса с минимальными накладными расходами — фактически разделяя вычисления и хранение.
Код «Энграмма» теперь полностью открыт на GitHub. Эта работа рассматривается как ключевое техническое раскрытие, лежащее в основе DeepSeek-V4, что сигнализирует о том, что условная память может стать основным примитивом моделирования для следующего поколения разреженных больших языковых моделей.
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Pandaily



