
В прошлом месяце OpenAI объявила о партнерстве с Cerebras, стартапом в области ИИ, который разрабатывает специализированные системы для ускорения обработки длинных выходных данных моделей ИИ. Тогда OpenAI заявила, что будет поэтапно интегрировать технологию Cerebras с низкой задержкой в свой стек для инференса, чтобы поддерживать различные рабочие нагрузки, включая генерацию кода и создание изображений.
Сегодня OpenAI анонсировала исследовательский предварительный просмотр GPT-5.3-Codex-Spark — уменьшенной версии GPT-5.3-Codex, разработанной для сценариев кодирования в реальном времени и работающей на базе Wafer Scale Engine 3 от Cerebras. OpenAI утверждает, что Codex-Spark может выдавать более 1000 токенов в секунду, сохраняя при этом высокую производительность. Однако, поскольку это меньшая модель, ожидается, что GPT-5.3-Codex-Spark не будет работать так же хорошо, как полная версия GPT-5.3-Codex; OpenAI заявляет, что ее производительность находится между GPT-5.3-Codex и GPT-5.1-Codex-Mini.
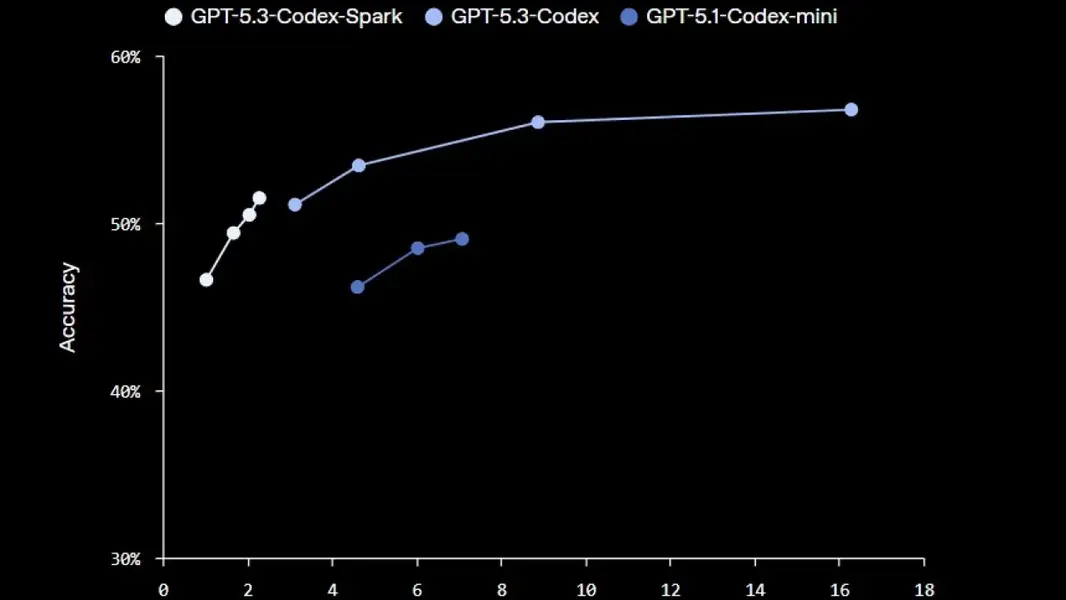
На данный момент Codex-Spark поддерживает контекстное окно 128K и ввод только текста. В будущем OpenAI планирует добавить поддержку более крупных моделей, более длинных контекстов и мультимодального ввода. Поскольку это ограниченный выпуск для пользователей ChatGPT Pro, модель будет иметь собственные ограничения скорости, хотя использование не будет учитываться в стандартных лимитах. В случае резкого роста спроса OpenAI может дополнительно ограничить доступ или временно поставить пользователей в очередь для поддержания надежности.
Подписчики ChatGPT Pro могут опробовать модель с ультранизкой задержкой, обновив Codex app, CLI и расширение VS Code до последних версий. OpenAI также предоставляет Codex-Spark через API для небольшой группы дизайн-партнеров, чтобы изучить, как разработчики хотят интегрировать ее в другие продукты и услуги.
OpenAI также подтвердила, что графические процессоры остаются основной вычислительной платформой для широкого использования в ее конвейерах обучения и инференса. Однако она позиционировала технологию Cerebras как более подходящую для рабочих нагрузок Codex, требующих чрезвычайно низкой задержки. Компания добавила, что графические процессоры и системы Cerebras также могут быть объединены в рамках одной рабочей нагрузки для достижения наилучшей общей производительности.
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Pradeep Viswanathan



