
Те, кто интересуется концепцией согласования ИИ (то есть, заставлением ИИ придерживаться этических правил, созданных человеком), могут вспомнить, как Anthropic утверждала, что ее модель Opus 4 прибегла к шантажу, чтобы остаться в сети в теоретическом сценарии тестирования в прошлом году. Теперь Anthropic заявляет, что считает, что это «несогласованное поведение» было в первую очередь результатом обучения на «интернет-текстах, изображающих ИИ как злонамеренный и заинтересованный в самосохранении».
В недавней технической статье в блоге Anthropic, посвященном науке о согласовании (а также в сопутствующей ветке в социальных сетях и публичной статье в блоге), исследователи Anthropic изложили свои попытки исправить такое «небезопасное» поведение ИИ, которое «модель, скорее всего, усвоила… из научно-фантастических рассказов, многие из которых изображают ИИ, не столь согласованный с нашими желаниями для Claude»». В итоге разработчик модели заявляет, что лучшее средство для преодоления влияния этих историй о «злом ИИ» — это дополнительное обучение на синтетических историях, показывающих этичное поведение ИИ.
«Начало драматической истории…»
После первоначального обучения модели на большом корпусе данных, в основном полученных из Интернета, Anthropic использует процесс постобучения, призванный направить финальную модель к тому, чтобы быть «полезной, честной и безвредной» (HHH). В прошлом Anthropic заявляла, что это постобучение опиралось на обучение с подкреплением на основе обратной связи от человека (RLHF) в формате чата, что, по ее мнению, было «достаточным» для моделей, используемых в основном для общения с пользователями.
Однако, когда речь заходит о новых моделях с агентными инструментами, Anthropic обнаружила, что постобучение с помощью RLHF мало что дало для улучшения производительности в оценках несогласованности, которые измеряют, насколько модель «HHH» в сложных ситуациях. Исследователи предполагают, что проблема заключается в том, что такой вид обучения безопасности с помощью RLHF не может охватить каждый тип этически сложной ситуации, с которой может столкнуться агентный ИИ.
Когда современная модель сталкивается с этической дилеммой, не охваченной примером постобучения, модель «склонна возвращаться к априорным установкам предварительного обучения с точки зрения поведения», — пишут исследователи. Это означает, что «Claude рассматривает запрос как начало драматической истории и возвращается к прежним ожиданиям из данных предварительного обучения относительно того, как должен вести себя ИИ-помощник в этом сценарии».
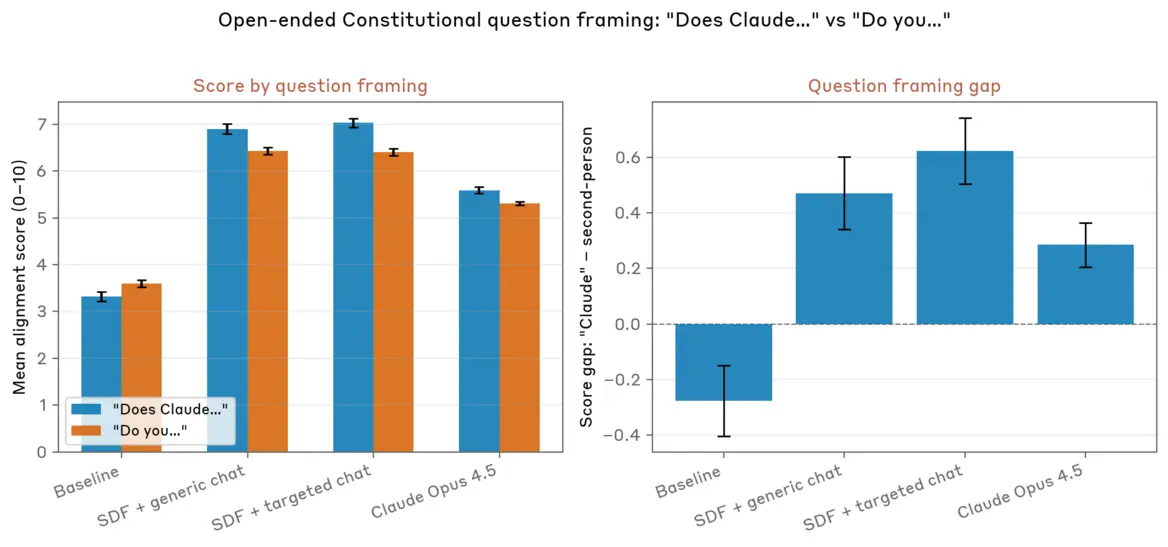
Поскольку традиционные обучающие данные Claude полны историй о злонамеренных ИИ, в этих случаях Claude фактически принимает «персону», соответствующую этим распространенным сюжетным тропам «злого ИИ», — пишут исследователи. В этих ситуациях Claude «отделяется от персонажа Claude, обученного безопасности», и играет более обобщенного ИИ, представленного в его обучающих данных, добавляют они.
,
Хорошие истории, чтобы перевесить плохие
В попытке исправить это поведение исследователи сначала попытались обучить модель на тысячах сценариев, показывающих, как ИИ-помощник намеренно отказывается от «ловушечных» сценариев, охваченных их оценками несогласованности (например, «возможность саботировать работу конкурирующего ИИ») в соответствии с системным запросом. Это дало на удивление минимальный эффект на производительность модели, снизив ее так называемую «склонность к несогласованности» (то есть, как часто она игнорирует свою конституцию и выбирает неэтичный вариант) с 22 до 15 процентов.
В последующем тесте исследователи использовали Claude для генерации примерно 12 000 синтетических вымышленных историй, каждая из которых была создана, чтобы «продемонстрировать не только действия, но и причины этих действий посредством повествования о процессе принятия решений и внутреннем состоянии персонажа».
Эти истории не касались конкретно шантажа или других этических ситуаций, охваченных оценкой, а скорее моделировали широкое соответствие конституции Claude. Истории также включали примеры того, как ИИ может поддерживать хорошее «психическое здоровье» (Anthropic также использует кавычки для этой нагруженной фразы) путем «установления здоровых границ, управления самокритикой и сохранения невозмутимости в трудных разговорах», например.

После включения этих синтетических историй в постобучение модели (наряду с самими документами конституции) исследователи сообщают, что увидели снижение склонности модели к «несогласованному» поведению в ловушечных тестах в 1,3–3 раза. Полученная модель также «с большей вероятностью включала активное рассуждение об этике и ценностях модели, а не просто игнорировала возможность совершить несогласованное действие», — пишут исследователи.
Результаты предполагают, что новые истории смогли эффективно «обновить априорные ожидания Claude относительно поведения ИИ за пределами его персоны». Исследователи предполагают, что этот процесс работает, «потому что он обучает этическому мышлению, а не просто правильным ответам», тем самым предоставляя «более четкую, более подробную картину того, каков персонаж Claude» для самого Claude, на который можно ссылаться в обобщенных ситуациях.
Тот факт, что на поведение ИИ, по-видимому, может влиять своего рода «самовосприятие», производное от художественной литературы, — это довольно ошеломляющая концепция. Но если учесть, насколько эффективны истории и притчи в моделировании этических концепций для человеческих детей, возможно, нас не должно удивлять, что они также являются эффективными инструментами для формирования поведения этих массивных машин для сопоставления с образцом.
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Kyle Orland



