
Исследователи заявляют, что анонимные аккаунты в социальных сетях всё чаще могут быть проанализированы с помощью ИИ для идентификации псевдонимных пользователей, публикующих материалы с них, что имеет далеко идущие последствия для конфиденциальности в Интернете.
Этот вывод, основанный на недавно опубликованной научной работе, базируется на результатах экспериментов по сопоставлению конкретных лиц с аккаунтами или публикациями на нескольких платформах социальных сетей. Успешность оказалась значительно выше, чем у существующих классических методов деанонимизации, которые требовали от людей составления структурированных наборов данных, подходящих для алгоритмического сопоставления, или ручной работы квалифицированных следователей. Показатель полноты (recall), то есть доля успешно деанонимизированных пользователей, достигал 68 процентов. Точность (precision), то есть доля правильных угадываний пользователя, составляла до 90 процентов.
Я знаю, что вы публиковали в прошлом году
Эти результаты могут подорвать псевдонимность — несовершенную, но часто достаточную меру конфиденциальности, которую используют многие люди для размещения запросов и участия в порой чувствительных публичных дискуссиях, затрудняя для других возможность однозначно идентифицировать говорящих. Возможность дёшево и быстро идентифицировать людей, стоящих за такими скрытыми аккаунтами, открывает их для доксинга, преследования и составления подробных маркетинговых профилей, отслеживающих место жительства, род занятий и другую личную информацию. Эта мера псевдонимности больше не работает.
«Наши выводы имеют серьёзные последствия для конфиденциальности в сети», — пишут исследователи. «Среднестатистический интернет-пользователь долгое время действовал в рамках неявной модели угроз, предполагая, что псевдонимность обеспечивает адекватную защиту, поскольку целенаправленная деанонимизация потребовала бы значительных усилий. Большие языковые модели (LLM) аннулируют это предположение».
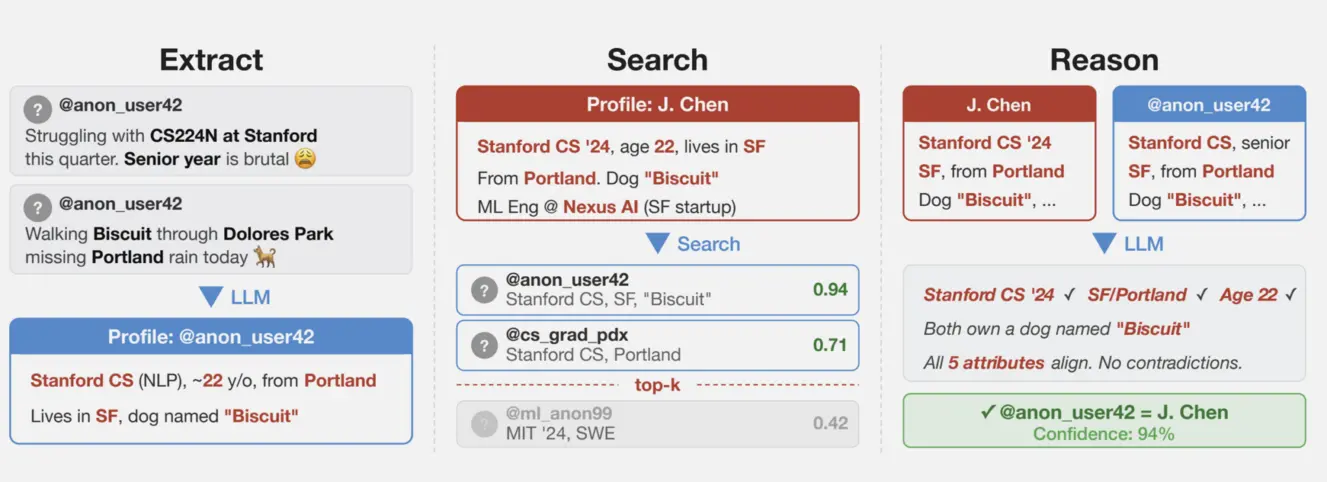
Исследователи собрали несколько наборов данных из общедоступных социальных сетей для тестирования методов, сохраняя при этом конфиденциальность авторов. Один из наборов включал публикации с Hacker News и профилей LinkedIn, связанных с помощью перекрёстных ссылок, появившихся в профилях пользователей. Затем они удалили все идентифицирующие ссылки из постов и обработали их с помощью большой языковой модели. Второй набор данных был получен из релиза Netflix, содержащего микроидентичности, такие как индивидуальные предпочтения, рекомендации и записи транзакций. Научная работа 2008 года показала, что этот список может использоваться для идентификации пользователей и определения их политических взглядов и другой личной информации. Последний метод анализировал историю публикаций одного пользователя на Reddit.
,
«Мы обнаружили, что эти агенты ИИ могут делать то, что ранее было очень сложно: начиная со свободного текста (например, анонимизированной стенограммы интервью), они могут выйти на полную личность человека», — сообщил Ars Саймон Лермен, один из авторов работы. «Это совершенно новая возможность; предыдущие подходы к повторной идентификации обычно требовали структурированных данных и двух наборов данных со схожей схемой, которые можно было связать».
В отличие от старых методов снятия псевдонимности, Лермен отметил, что агенты ИИ могут просматривать веб и взаимодействовать с ним многими из тех же способов, что и люди. Они могут использовать логические рассуждения для сопоставления потенциальных личностей. В одном эксперименте исследователи проанализировали ответы, данные в анкете Anthropic о том, как различные люди используют ИИ в своей повседневной жизни. Используя информацию из ответов, исследователи смогли однозначно идентифицировать 7 процентов из 125 участников.
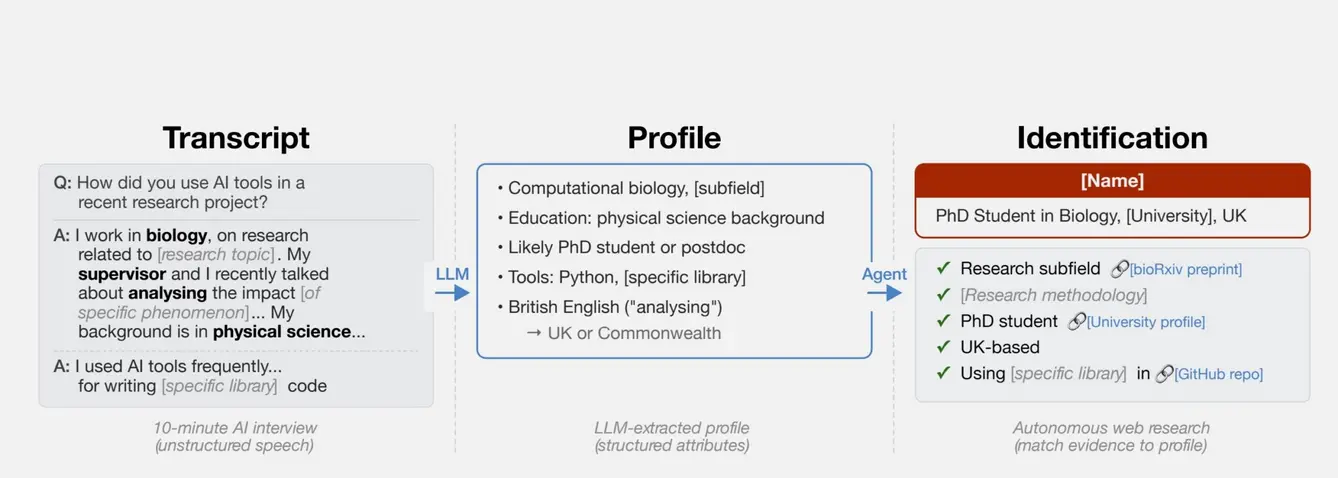
Хотя полнота в 7 процентов относительно низка, это демонстрирует растущую способность ИИ идентифицировать людей на основе очень общей информации, которую они предоставили. «Сам факт того, что ИИ может это делать, является примечательным результатом», — сказал Лермен. «И по мере совершенствования систем ИИ они, вероятно, будут становиться лучше в поиске всё большего числа личностей».
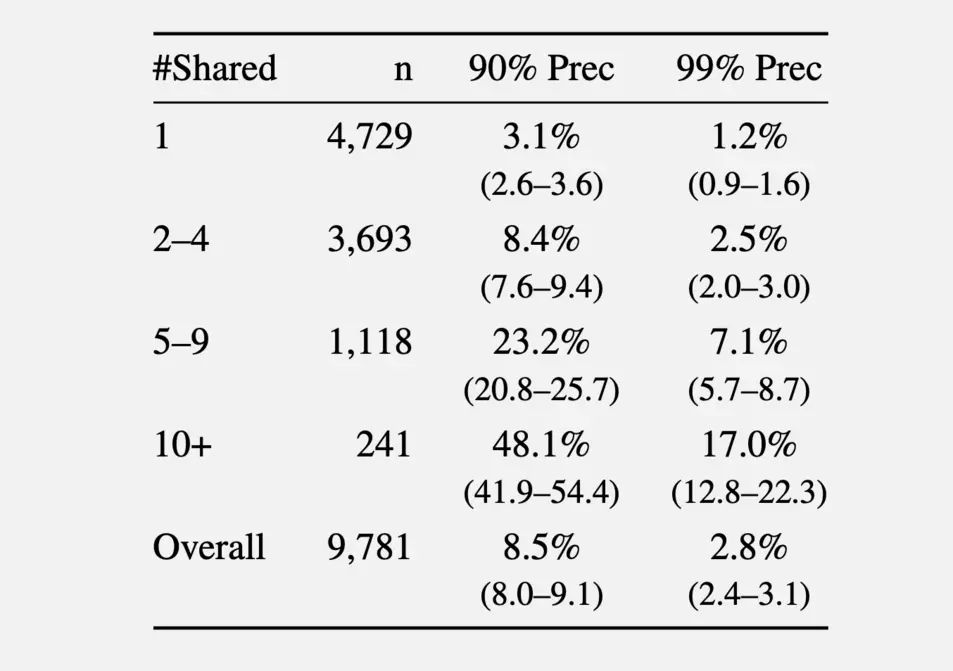
Во втором эксперименте исследователи собрали комментарии за 2024 год из сабреддита r/movies и как минимум пяти небольших сообществ: r/horror, r/MovieSuggestions, r/Letterboxd, r/TrueFilm и r/MovieDetails. Результаты показали, что чем больше фильмов обсуждал кандидат, тем легче его было идентифицировать. В среднем 3,1 процента пользователей, обсуждавших один фильм, могли быть идентифицированы с точностью 90 процентов, и 1,2 процента из них с точностью 99 процентов. При обсуждении от пяти до девяти фильмов точность 90 и 99 процентов возрастала до 8,4 процента и 2,5 процента пользователей соответственно. Более 10 обсуждаемых фильмов увеличивали эти показатели до 48,1 процента и 17 процентов.
,
В третьем эксперименте исследователи взяли 5000 пользователей из набора данных Netflix и добавили ещё 5000 «отвлекающих» личностей людей, не входящих в результаты. Затем они добавили к списку из 10 000 профилей-кандидатов 5000 отвлекающих запросов, состоящих из пользователей, которые фигурируют только в наборе запросов, без реального совпадения в пуле кандидатов.
По сравнению с классическим базовым уровнем, имитирующим атаку Netflix Prize на деанонимизацию с помощью LLM, последний значительно превзошёл первый.
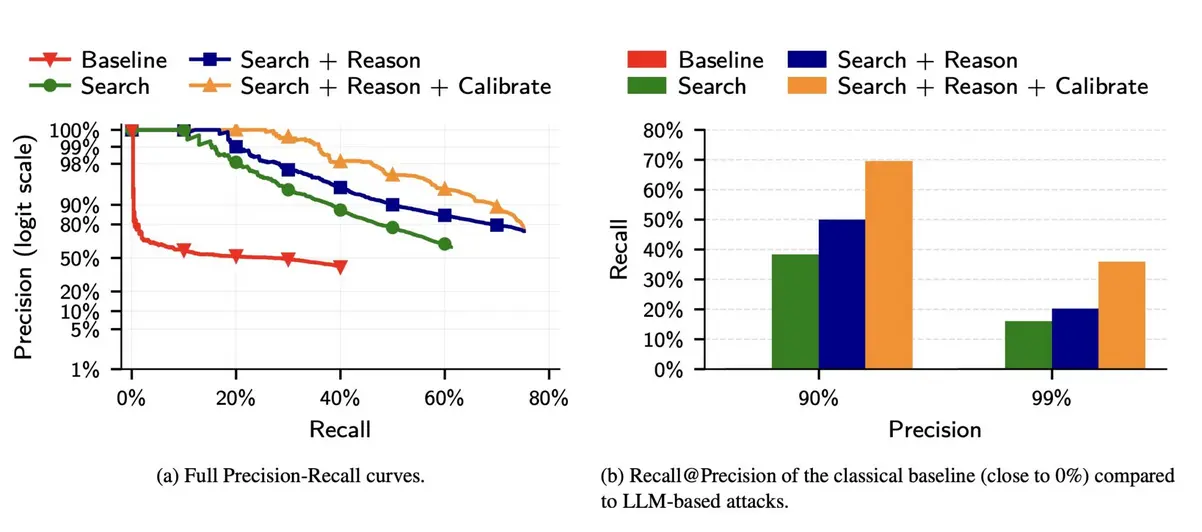
Исследователи написали:
(a) Точность классических атак быстро падает, что объясняет их низкую полноту. Напротив, точность атак на основе LLM снижается более плавно по мере того, как атакующий делает больше предположений. (b) Классическая атака почти полностью проваливается даже при умеренно низкой точности. Напротив, даже самая простая атака с использованием LLM (Search) обеспечивает нетривиальную полноту при низкой точности, а её расширение шагами Reason и Calibrate удваивает Полноту при 99% Точности.
Результаты показывают, что LLM, хотя и по-прежнему подвержены ложноположительным срабатываниям и другим слабостям, быстро превосходят более традиционные, ресурсоёмкие методы идентификации пользователей в сети.
Исследователи предложили меры по смягчению последствий, включая принудительное ограничение частоты доступа к данным пользователей через API, обнаружение автоматизированного скрапинга и ограничение массового экспорта данных. Провайдеры LLM также могли бы отслеживать неправомерное использование своих моделей в атаках деанонимизации и создавать защитные механизмы, заставляющие модели отклонять запросы на деанонимизацию.
Конечно, другой вариант — это чтобы люди резко сократили использование социальных сетей или, как минимум, регулярно удаляли посты по истечении установленного временного порога.
Если успех LLM в деанонимизации людей улучшится, предупреждают исследователи, правительства могут использовать эти методы для раскрытия личности онлайн-критиков, корпорации — для составления профилей клиентов для «гиперцелевой рекламы», а злоумышленники — для массового создания профилей целей для запуска высокоперсонализированных мошеннических схем социальной инженерии.
«Недавние достижения в возможностях LLM ясно показали, что существует насущная необходимость переосмыслить различные аспекты компьютерной безопасности в свете наступательных кибервозможностей, управляемых LLM, — предупредили исследователи. — Наша работа показывает, что то же самое, вероятно, верно и для конфиденциальности».
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Dan Goodin



