
Китайская лаборатория искусственного интеллекта DeepSeek заявляет, что ее новейшая модель V4 значительно сокращает вычислительные ресурсы, необходимые для вывода токенов, и объем памяти, согласно ее примечаниям к выпуску. DeepSeek утверждает, что модель ИИ V4 требует всего 27% от FLOPs для вывода одного токена и 10% кэша ключ-значение (KV) по сравнению с ее предшественником, моделью DeepSeek V3.2. Сокращение требований к кэшу решает проблему с потреблением памяти: меньшие требования экономят память и увеличивают контекст, доступный разработчикам моделей при их создании.
DeepSeek V4 Демонстрирует Прогресс в Использовании Кэша и Операциях, Необходимых для Обработки Одного Токена
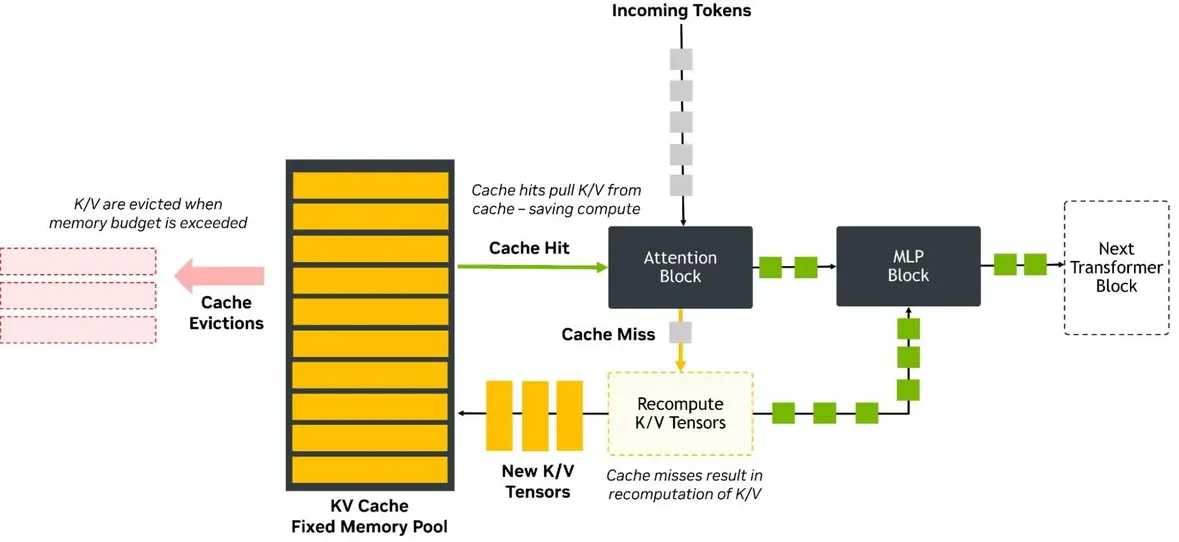
В примечаниях к выпуску DeepSeek V4 компания DeepSeek указывает, что новая модель способна использовать всего 27% FLOPs для вывода одного токена и 10% кэша ключ-значение (KV) при работе с окном контекста в один миллион токенов. Окно контекста — это объем текста, который большая языковая модель искусственного интеллекта может обработать, прежде чем ей потребуется освободить ресурсы памяти.
Это улучшенное использование памяти особенно важно на этапе декодирования (Decode) вычислений ИИ, который в целом делится на две фазы: предварительное заполнение (Prefill) и декодирование (Decode). Поскольку модель ИИ генерирует выходные данные на этапе декодирования, ей необходимо хранить контекст разговора или запроса, полученного на этапе предварительного заполнения. В результате этап декодирования требует больше памяти, чем предварительное заполнение, особенно в отношении кэша ключ-значение (KV).
Последние Усовершенствования Основаны на Ранних Функциях Моделей DeepSeek
По мере увеличения числа токенов в контексте растут и требования к кэшу KV, что означает, что при одном миллионе токенов модель, использующая меньше кэша, способна обрабатывать больше запросов или требовать меньше ресурсов памяти.
Другое заявление DeepSeek о том, что модель V4 требует 27% FLOPs для вывода одного токена, улучшает производительность только при условии достаточного объема памяти, доступного для выполнения вычислений на GPU. Кроме того, использование значительно меньшего объема кэш-памяти требует от модели идти на компромиссы, которые могут привести к потере специфических деталей. Это называется сбоем «иголка в стоге сена» и может привести к неточным результатам.
Последние улучшения основаны на архитектуре Multi-Head Latent Attention от DeepSeek, которую компания представила в более ранних моделях. Эта архитектура была разработана с учетом ограничений памяти, поскольку она сжимает ключ и значение модели в единый блок, который затем разворачивается во время вычислений, чтобы модель могла эффективно использовать ресурсы.
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Ramish Zafar



