
Очередной день — очередная модель ИИ от Google. На этот раз Google DeepMind представила нового члена семейства открытых моделей Gemma 4, но она принципиально отличается от остальных моделей линейки. DiffusionGemma генерирует выходные данные не линейно, как большинство моделей ИИ. Вместо этого она способна параллельно создавать целый блок текста. Google заявляет, что это делает ее быстрее и эффективнее при работе на локальном оборудовании, таком как Nvidia DGX или обычная игровая видеокарта.
Большинство моделей ИИ спроектированы как авторегрессионные — они генерируют текст слева направо, по одному токену за раз. DiffusionGemma имеет больше общего с моделями генерации изображений, которые начинают со статического шума, а затем “очищают” его для создания желаемого контента. Эта модель использует поле токенов-заполнителей, многократно проходя по “холсту” для генерации вероятных токенов и используя их для улучшения оценки остальных. В конце процесса модель фиксирует свои токенные выводы одним большим блоком — “очищенным” текстовым холстом.
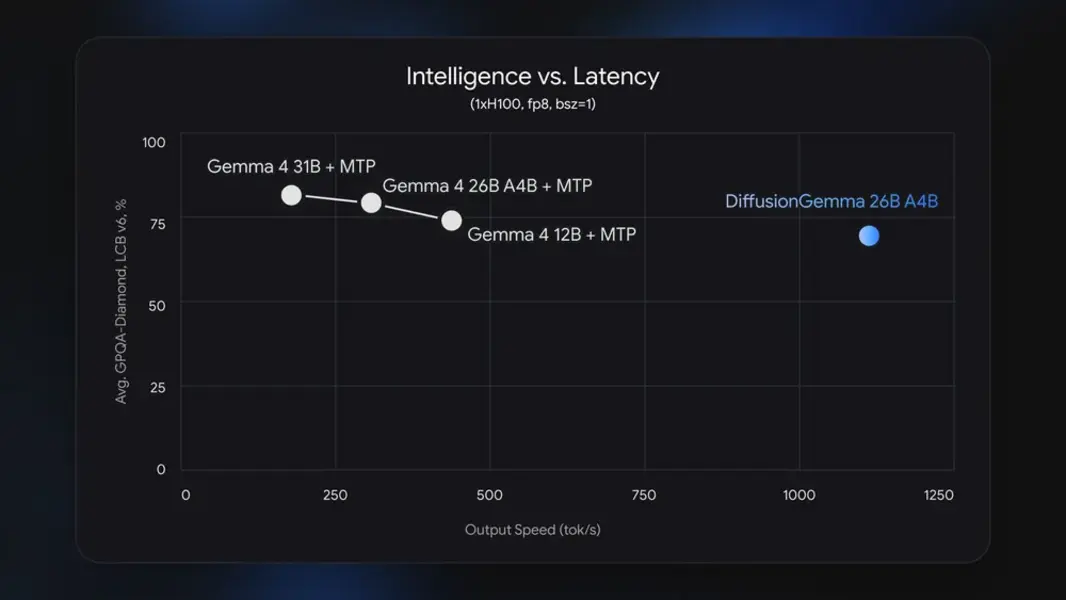
DiffusionGemma довольно крупная по меркам открытых моделей Google. Это модель Mixture of Experts (MoE) с общим числом параметров 26 миллиардов, но во время инференса активируются только 3,8 миллиарда. Это означает, что она должна поместиться в лимит оперативной памяти в 18 ГБ высокопроизводительной видеокарты. В тестах с RTX 5090 DiffusionGemma выдает около 700 токенов в секунду. С одним AI-ускорителем Nvidia H100 DiffusionGemma может генерировать более 1000 токенов в секунду. Это примерно в четыре раза больше, чем у сопоставимых по размеру авторегрессионных моделей Gemma.
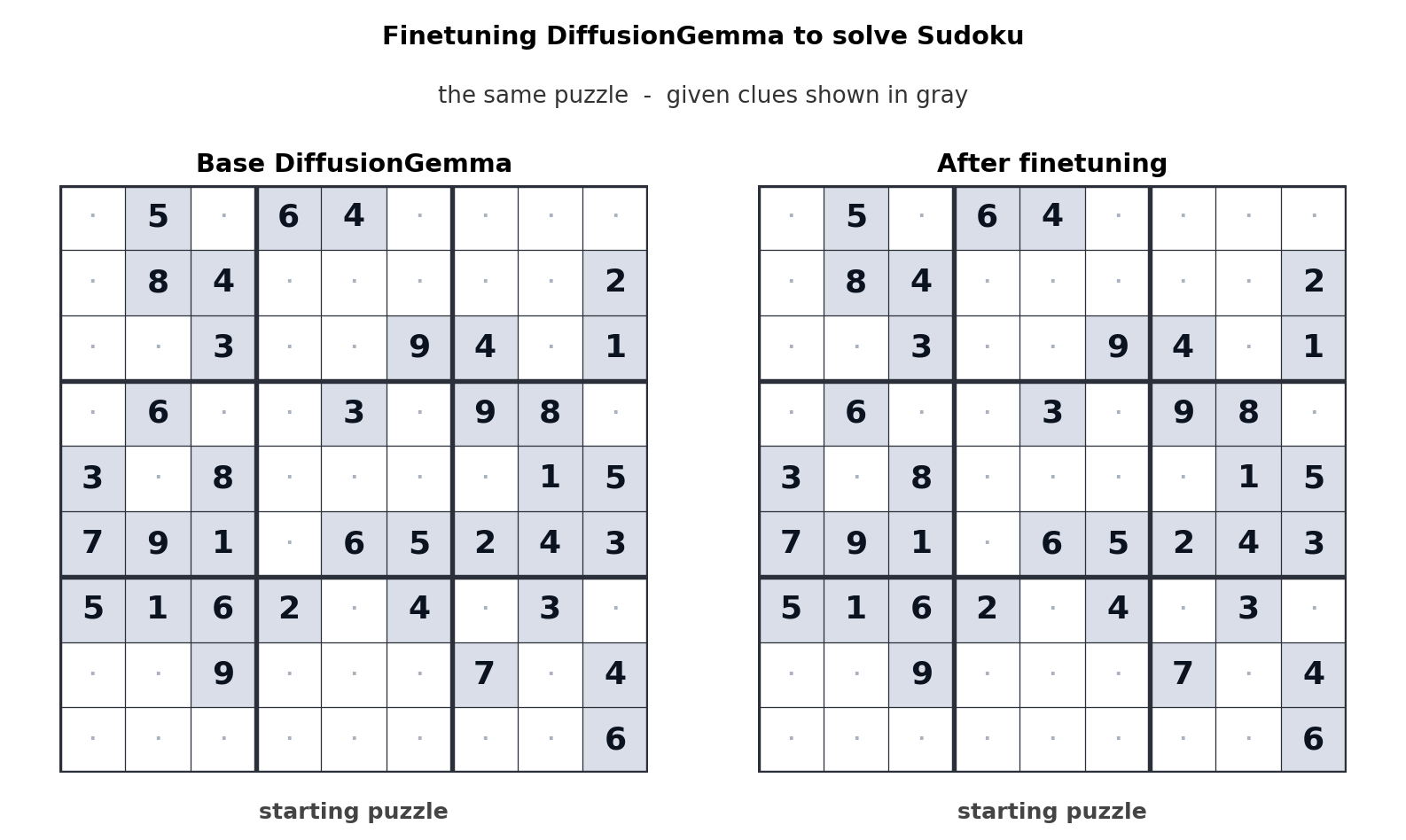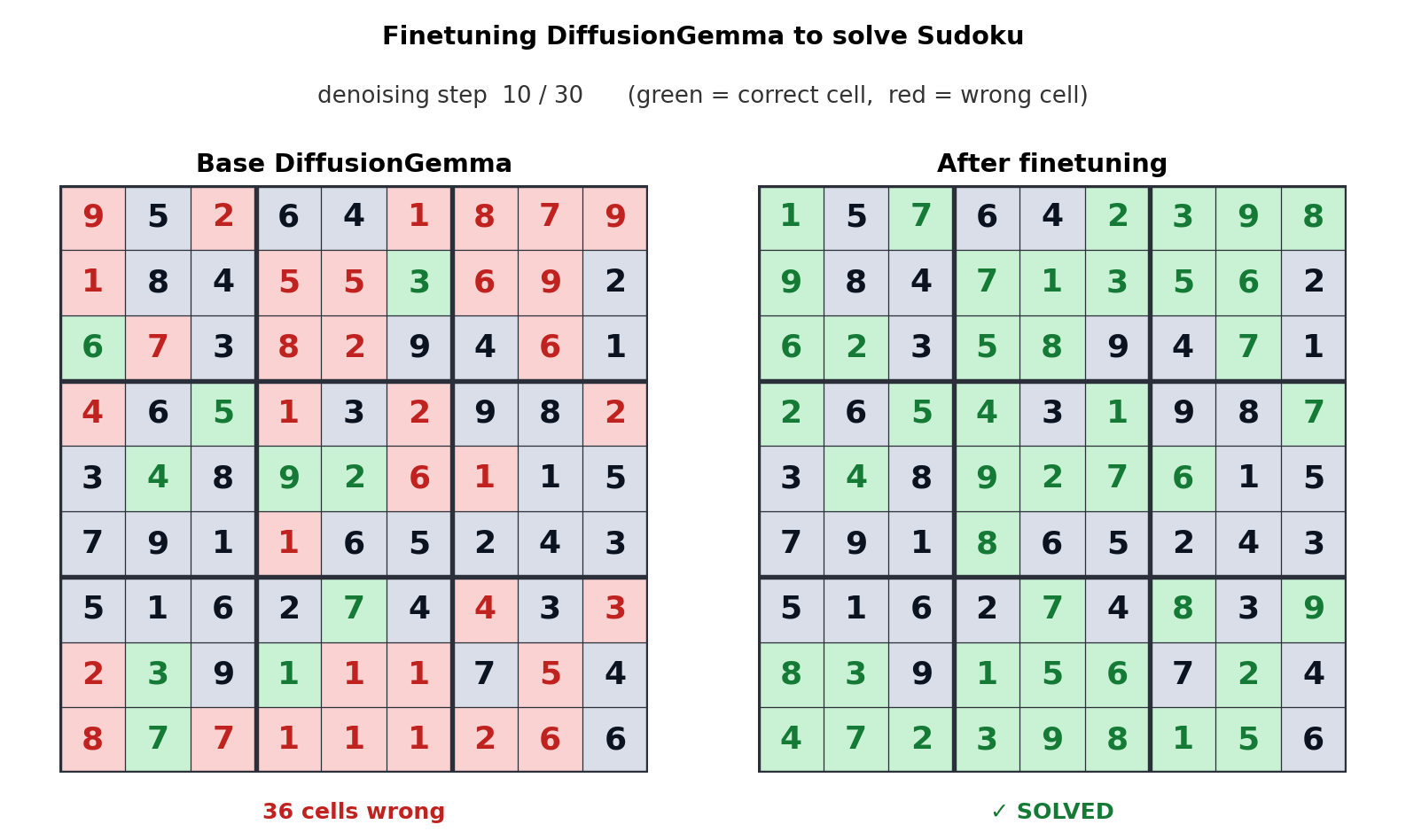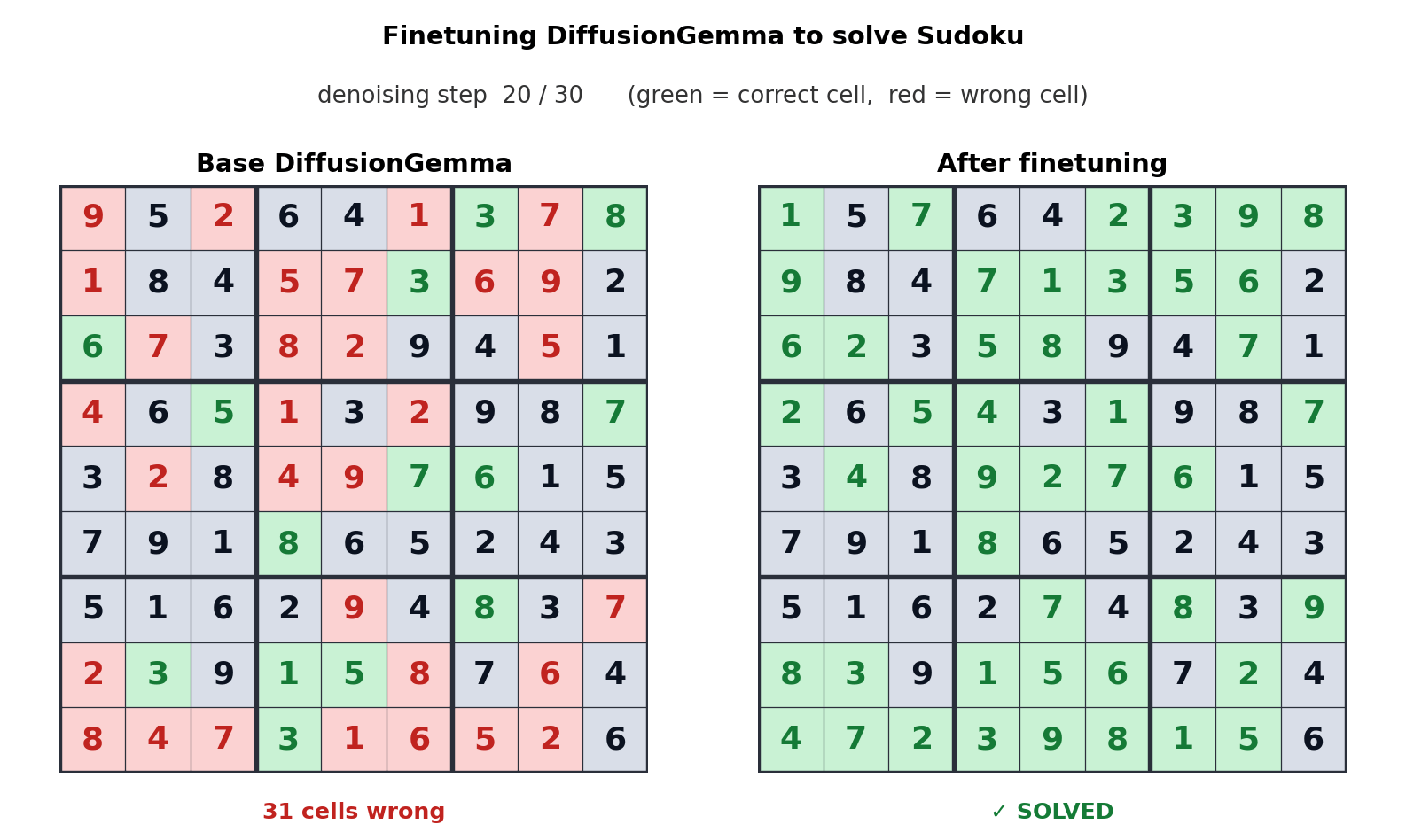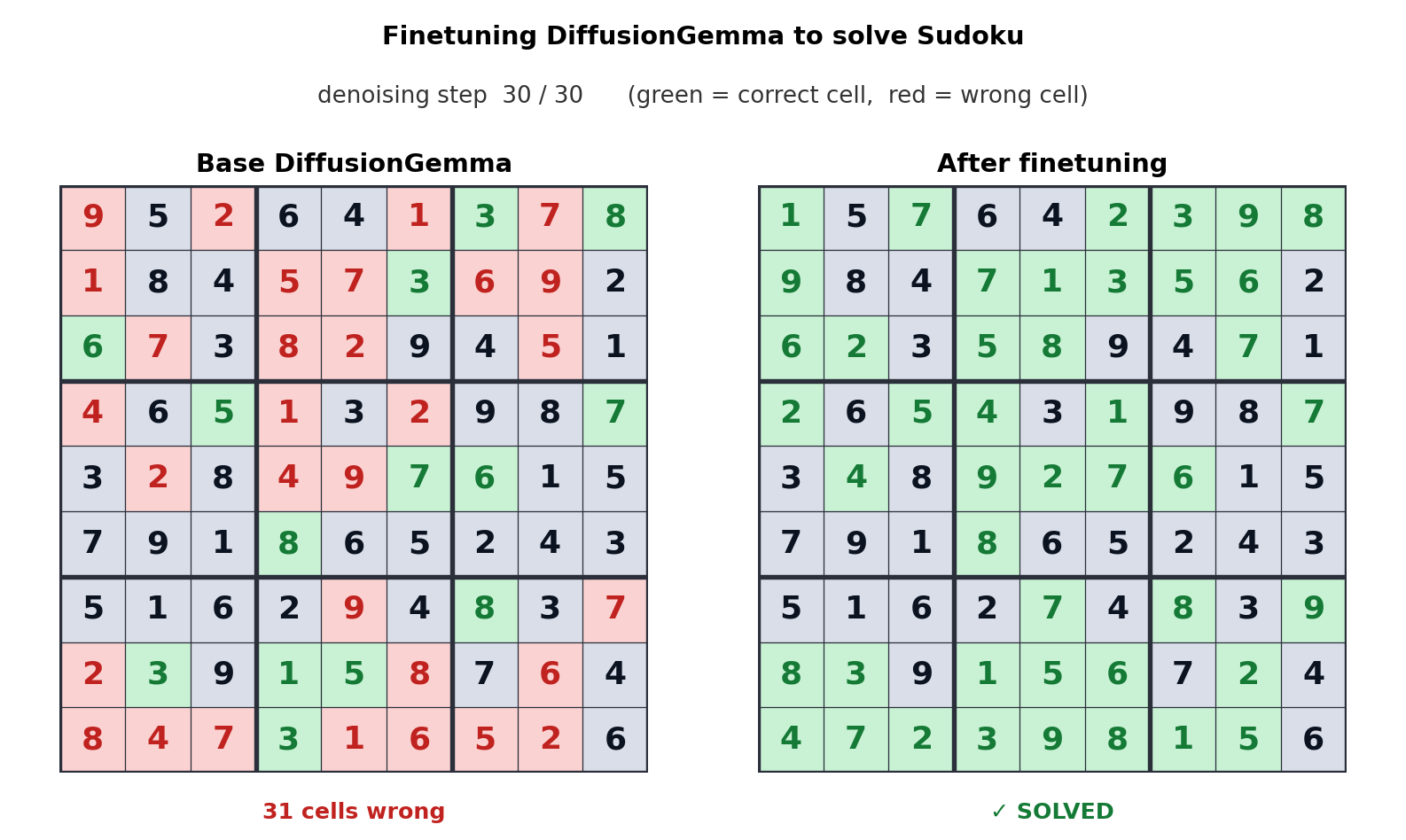
Такой подход к генерации текста смещает узкое место с пропускной способности памяти на вычислительную мощность, позволяя генерировать до 256 токенов параллельно. Google заявляет, что это дает ощутимый прирост в нелинейных задачах, таких как редактирование “на лету”, молекулярное секвенирование и математическая графическая визуализация. Анимация выше показывает, как DiffusionGemma была настроена для решения головоломок Судоку, что является заведомо сложной задачей для стандартных авторегрессионных моделей ИИ, поскольку каждый токен зависит от будущих токенов. Способность DiffusionGemma непрерывно самокорректировать большие наборы токенов упрощает эту задачу.
Множество путей к локальной эффективности
Если диффузия настолько быстрее, почему Google не использует ее в больших облачных моделях Gemini? Google экспериментировала с этим, но у текстовой диффузии есть несколько недостатков, включая более высокий уровень ошибок. В моделях диффузии изображений один плохо предсказанный пиксель не делает изображение бесполезным, но язык дискретен. Эквивалентная ошибка в тексте может сделать блок токенов бессмысленным, и вам придется начинать заново, чтобы получить лучший результат. Диффузионные модели также тратят ресурсы, когда желаемый результат состоит всего из нескольких токенов. Им приходится выполнять гораздо больше параллельной работы, чтобы свести результат к нескольким токенам, что авторегрессионная модель делает от начала до конца всего за пять шагов.
Однако выигрыш в эффективности для локальной обработки делает это направление экспериментов привлекательным. В облаке авторегрессионные модели могут объединять большие объемы вычислительных задач от множества пользователей, поэтому они постоянно генерируют токены, а используемая в таких системах высокоскоростная память (HBM) гораздо эффективнее перемещает данные.
И наоборот, локальный ИИ сталкивается с потерями циклов вычислений из-за более низкой пропускной способности памяти и времени простоя. Диффузионные модели могут более эффективно использовать доступные вычисления, но это не единственный способ. Google также недавно начала внедрять “драфтеры” Multi-Token Prediction (MTP), которые используют простаивающие циклы вычислений для предсказания возможных токенов, чтобы увеличить скорость. Но диффузия даже быстрее версий Gemma с MTP.
Google подчеркивает, что DiffusionGemma является экспериментальной, но она доступна под той же лицензией Apache 2.0, что и все остальные модели Gemma четвертого поколения. Вы можете скачать веса модели уже сегодня с Hugging Face. Google заявляет, что работала с Nvidia, чтобы обеспечить оптимизацию DiffusionGemma для различных конфигураций, включая высокопроизводительные графические процессоры RTX (квантованные) и корпоративные системы, такие как H100 или платформа DGX Spark.
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Ryan Whitwam



