
Генеральный директор NVIDIA, Дженсен Хуанг, возможно, преподнёс своей команде разработчиков чипов “рождественский” подарок, которого никто не ожидал. Появились сообщения о том, что “зелёная команда” заключила соглашение с Groq, компанией, специализирующейся на разработке специализированного оборудования для искусственного интеллекта. И это не просто чипы; они могут стать для NVIDIA путём к доминированию в задачах логического вывода.
Чтобы понять, почему это “мастер-класс”, необходимо рассмотреть два различных фронта: нормативные лазейки, которые Дженсен только что использовал, и аппаратное доминирование, которое он обеспечил.
Выглядит как приобретение. Пахнет как приобретение. Но на бумаге это всего лишь “неисключительное” соглашение
CNBC первым сообщил об этом событии, заявив, что NVIDIA “покупает” Groq Inc. в рамках мега-сделки на 20 миллиардов долларов, что станет крупнейшим приобретением Дженсена. Это привело к масштабному пожару в отрасли, где одни предполагали, что нормативные расследования помешают этому шагу, а другие утверждали, что это конец Groq. Однако позже Groq официально опубликовала заявление на своем веб-сайте, в котором говорится, что она заключила “неисключительное лицензионное соглашение” с NVIDIA, предоставляющее AI-гиганту доступ к технологии логического вывода.
Таким образом, восприятие слияния, по крайней мере на бумаге, было аннулировано после заявления Groq. Теперь последовательность событий кажется мне довольно интересной, тем более что единственное, чего не хватает этой сделке, чтобы считаться полномасштабным приобретением, – это избежание упоминания об этом в официальных документах.
Это классический ход “обратного приобретения” от NVIDIA, и если кто-то не знает, что это значит, то это ход из учебника Microsoft, когда технологический гигант еще в 2024 году объявил о сделке с Inflection на 653 миллиона долларов, которая включает в себя таких людей, как Мустафа Сулейман и Карен Симоня, присоединяющихся к Microsoft, которые возглавили AI-стратегию фирмы.

Обратное приобретение означает, что компания нанимает ключевых специалистов из стартапа, оставляя позади “минимальную” корпоративную структуру, что в конечном итоге не позволяет считать такой шаг слиянием. Теперь кажется, что Дженсену удалось осуществить нечто подобное, чтобы избежать расследования FTC, поскольку, представив сделку с Groq как “неисключительное лицензионное соглашение”, NVIDIA по сути находится вне сферы действия Закона Харта-Скотта-Родино (HSR). Интересно, что Groq упоминает, что GroqCloud продолжит работать, но только как “голая структура”.
Произошло то, что NVIDIA приобрела таланты и интеллектуальную собственность Groq за заявленные 20 миллиардов долларов, сумела избежать нормативных расследований, что позволило им заключить сделку в считанные дни. А когда речь заходит об оборудовании, к которому они теперь имеют доступ, это самая интересная часть сделки NVIDIA-Groq.
Архитектура LPU от Groq и почему она может стать недостающим звеном для доминирования NVIDIA в классе логического вывода
Это тот сегмент, который мне больше всего нравится обсуждать, поскольку у Groq есть аппаратная экосистема, которая может повторить успех NVIDIA в эпоху обучения, и я обосную это в дальнейшем. Индустрия искусственного интеллекта резко эволюционировала за последние несколько месяцев с точки зрения вычислительных потребностей. В то время как такие компании, как OpenAI, Meta, Google и другие, занимаются обучением передовых моделей, они также стремятся иметь надежный стек логического вывода на борту, поскольку именно здесь большинство гиперскейлеров зарабатывают деньги.
Когда Google анонсировала Ironwood TPU, отрасль восприняла это как вариант, ориентированный на логический вывод, и ASIC рекламировались как замена NVIDIA, главным образом потому, что были утверждения, что Дженсен еще не предложил решение, которое доминировало бы в пропускной способности логического вывода. У нас есть Rubin CPX, но я расскажу об этом позже. Когда мы говорим о логическом выводе, вычислительные потребности резко меняются, поскольку при обучении отрасли требуется пропускная способность по сравнению с задержкой и высокой арифметической интенсивностью, поэтому современные ускорители оснащены HBM и массивными тензорными ядрами.

Поскольку гиперскейлеры переходят к логическому выводу, им теперь требуется быстрый, предсказуемый и прямой механизм выполнения, поскольку задержка ответа является основным узким местом. Чтобы обеспечить быструю вычислительную мощность, такие компании, как NVIDIA, нацелились на такие рабочие нагрузки, как логический вывод с массивным контекстом (предварительное заполнение и общий логический вывод) с помощью Rubin CPX, или Google, которая рекламирует себя как более энергоэффективный выбор с помощью TPU. Однако, когда дело доходит до декодирования, доступно не так много вариантов.
Декодирование относится к фазе генерации токенов логического вывода в модели-трансформере, и оно становится все более важным в качестве ключевого аспекта классификации рабочих нагрузок AI. Декодирование требует детерминированного поведения с низкой задержкой, и, учитывая ограничения, вызванные использованием HBM (задержка и мощность) в средах логического вывода, у Groq есть нечто уникальное – использование SRAM (статической оперативной памяти). Теперь пришло время поговорить об LPU, теперь, когда я дал понять, почему необходимо по-новому взглянуть на вычисления логического вывода.
LPU от Groq: сочетание декодирования с высокой задержкой и превосходство над другими в предсказуемости на токен
LPU – это детище бывшего генерального директора Groq, Джонатана Росса, который, кстати, присоединяется к NVIDIA после недавней договоренности. Росс известен своей работой с TPU от Google, поэтому мы можем быть уверены, что Team Green приобретает важный актив внутри компании. LPU (блоки обработки языка) — это решение Groq для рабочих нагрузок класса логического вывода, и компания отличается от других тем, что основана на двух основных ставках. Первая — это детерминированное выполнение и встроенная SRAM в качестве основного хранилища весов. Это подход Groq к достижению скорости за счет обеспечения предсказуемости.
Groq ранее продемонстрировала два ведущих решения: свой GroqChip и GroqCard на базе партнеров. Основываясь на информации, опубликованной в официальных документах, эти чипы имеют 230 МБ встроенной SRAM с пропускной способностью встроенной памяти до 80 ТБ/с. Использование SRAM является одним из ключевых преимуществ LPU, поскольку оно обеспечивает на несколько порядков меньшую задержку. С HBM, когда вы учитываете задержку, вызванную доступом к DRAM и очередями контроллера памяти, SRAM выигрывает со значительным отрывом. Встроенная SRAM позволяет Groq достигать десятков терабайт в секунду внутренней пропускной способности, что позволяет фирме обеспечивать ведущую пропускную способность.
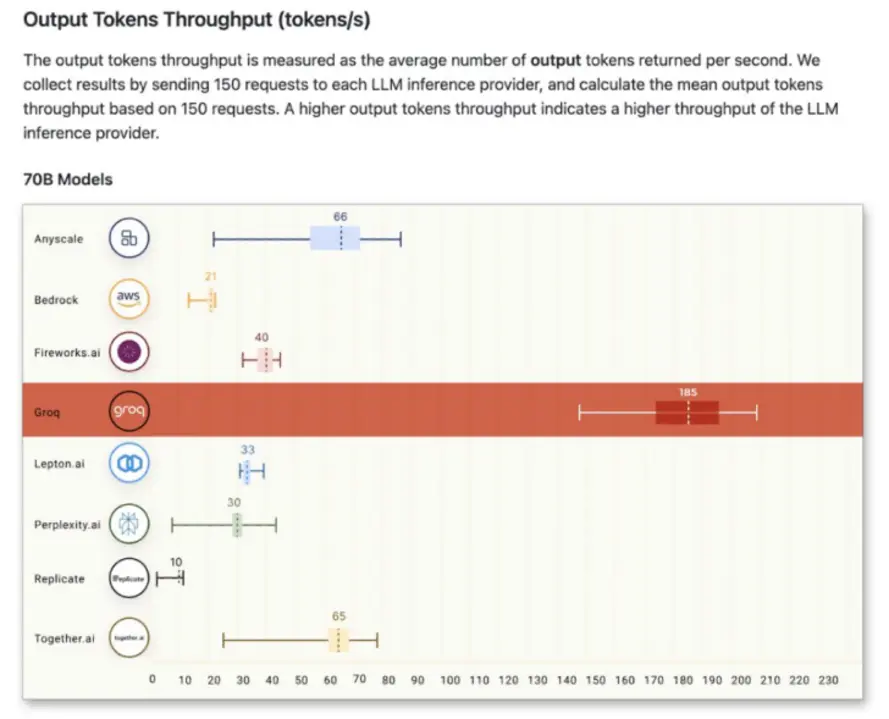
SRAM также позволяет Groq предлагать энергоэффективную платформу, поскольку доступ к SRAM требует значительно меньшей энергии на бит и устраняет накладные расходы PHY. И при декодировании LPU приводят к значительному улучшению энергопотребления на токен, что является важным фактором, учитывая, что рабочие нагрузки декодирования требуют больших объемов памяти. Это архитектурный аспект LPU, и хотя он может показаться значительным, это всего лишь одна часть того, как работают LPU. Другой элемент — использование детерминированных циклов, который фокусируется на планировании во время компиляции для устранения временных вариаций между ядрами.
Планирование во время компиляции гарантирует, что “задержки” в конвейерах декодирования отсутствуют, и это важный фактор, поскольку он обеспечивает идеальное использование конвейера, обеспечивая гораздо более высокую пропускную способность по сравнению с современными ускорителями. Подводя итог, LPU полностью посвящены тому, что нужно гиперскейлерам для логического вывода, но есть одна оговорка, которую отрасль в настоящее время игнорирует. LPU — это реальное и эффективное оборудование для логического вывода, но они очень специализированные и еще не стали основной платформой по умолчанию, и именно здесь вступает в дело NVIDIA.

Хотя мы до сих пор не знаем, как LPU можно интегрировать в предложения NVIDIA, один из способов сделать это — предложить их в составе систем логического вывода масштаба стойки (аналогично Rubin CPX) в сочетании с сетевой инфраструктурой. Это позволило бы графическим процессорам обрабатывать предварительное заполнение/длинный контекст, а LPU — сосредоточиться на декодировании, что по сути означает, что в задачах логического вывода у NVIDIA все в порядке. Это может превратить имидж LPU из экспериментального варианта в стандартный метод логического вывода, обеспечив их широкое распространение среди гиперскейлеров.

Нет сомнений в том, что эта сделка знаменует собой одно из самых больших достижений NVIDIA в плане расширения своего портфеля, поскольку все указывает на то, что логический вывод будет следующим вариантом, о котором будет говорить NVIDIA, а LPU станут основной частью стратегии компании для этой области рабочих нагрузок AI. Что ж, на этом все, что касается анализа сделки с Groq, и Дженсен, безусловно, сделал потрясающий подарок людям из NVIDIA, а также технически подкованным людям, таким как я.
Всегда имейте в виду, что редакции некоторых изданий могут придерживаться предвзятых взглядов в освещении новостей.
8/6
Автор – Muhammad Zuhair




{kind=link}
{kind=link}