
В четверг Google выпустила волну новых моделей Gemma с открытыми весами, оптимизированных для агентного ИИ и кодирования, под более разрешительной лицензией Apache 2.0, нацеленной на привлечение предприятий.
Запуск происходит на фоне нашествия китайских больших языковых моделей (LLM) с открытыми весами от Moonshot AI, Alibaba и Z.AI, многие из которых теперь соперничают с GPT-5 от OpenAI или Claude от Anthropic.
Своим последним релизом Google предлагает корпоративным клиентам отечественную альтернативу, которая, однако, не будет поглощать конфиденциальные корпоративные данные для обучения будущих моделей.
Разработанное командой DeepMind от Google, четвертое поколение моделей Gemma несет ряд улучшений, включая «продвинутое рассуждение» для повышения производительности в математике и следовании инструкциям, поддержку более чем 140 языков, нативное вызов функций, а также видео- и аудиовходы.
Как и предыдущие модели Gemma, Google делает их доступными в различных размерах для приложений, варьирующихся от одноплатных компьютеров и смартфонов до ноутбуков и корпоративных дата-центров.
На вершине стека находится LLM с 31 миллиардом параметров, которая, по утверждению Google, была настроена для максимизации качества вывода.
Учитывая свой размер, модель не рискует каннибализировать более крупные проприетарные модели Google, но при этом достаточно мала, чтобы предприятиям не пришлось тратить сотни тысяч долларов на GPU-серверы для ее запуска или дообучения.
По данным Google, модель может работать без квантования при 16-битном формате на одном H100 с 80 ГБ. В то же время при 4-битном разрешении модель достаточно мала, чтобы поместиться на GPU с 24 ГБ, таком как Nvidia RTX 4090 или AMD RX 7900 XTX, с использованием таких фреймворков, как Llama.cpp или Ollama.
Для приложений, требующих более низкой задержки, то есть более быстрого отклика, линейка Gemma 4 также включает модель с 26 миллиардами параметров, использующую архитектуру «смесь экспертов» (MoE).
Во время инференса для обработки и генерации каждого токена используется подмножество из 128 экспертов модели, что составляет 3,8 миллиарда активных параметров. Пока модель помещается в вашу VRAM, она может генерировать токены намного быстрее, чем плотная модель эквивалентного размера.
Эта более высокая скорость достигается ценой более низкого качества вывода, поскольку для обработки вывода используется лишь часть параметров. Однако это может быть оправдано при работе на устройствах с более медленной памятью, например, на ноутбуке или потребительской видеокарте.
Обе эти модели имеют контекстное окно в 256 000 токенов, что делает их подходящими для локальных помощников по коду — сценария использования, который Google стремилась подчеркнуть в своем анонсе запуска.
Наряду с этими моделями представлена пара LLM, оптимизированных для периферийного оборудования низкого класса, такого как смартфоны и одноплатные компьютеры, например, Raspberry Pi. Эти модели доступны в двух размерах: одна с двумя миллиардами эффективных параметров, а другая — с четырьмя миллиардами.
Ключевое слово здесь — «эффективные». Фактически модели имеют 5,1 и 8 миллиардов параметров соответственно, но за счет использования послойных встраиваний (PLE) Google удается снизить эффективный размер модели с точки зрения вычислений до 2,3–4,5 миллиардов параметров, что делает их более эффективными для работы на устройствах с ограниченными вычислительными ресурсами или батареями.
Несмотря на свой размер, обе модели по-прежнему предлагают контекстное окно в 128 000 токенов и являются мультимодальными, что означает, что, помимо текста, они могут принимать в качестве входных данных визуальные и аудиоданные (только E2B/E4B).
Как и во всех бенчмарках, предоставляемых поставщиками, к этим заявлениям следует относиться с долей скептицизма, но по сравнению с Gemma 3 Google заявляет о значительном улучшении производительности в ряде ИИ-бенчмарков:
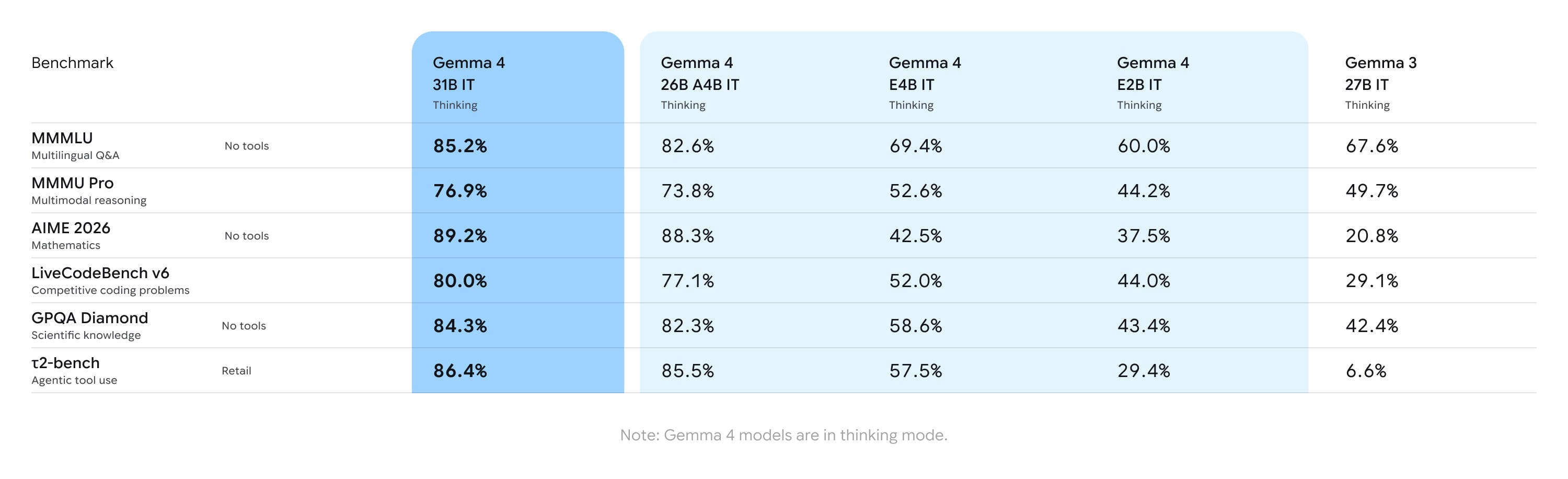
Вот краткий обзор того, как, по мнению Google, Gemma 4 соотносится с моделями с открытыми весами предыдущего поколения — Нажмите для увеличения
Но, возможно, самое значительное изменение в Gemma 4 — это переход к более разрешительной лицензии Apache 2.0, которая предоставляет предприятиям гораздо больше гибкости в том, как и где они могут использовать или развертывать модели.
Ранее лицензия Google Gemma запрещала использование моделей в определенных сценариях и оставляла за собой право прекратить доступ пользователя, если он не соблюдает правила.
Переход на Apache 2.0 теперь означает, что предприятия могут развертывать модели, не опасаясь, что Google внезапно отзовет поддержку.
Gemma 4 доступна в сервисах Google AI Studio и AI Edge Gallery, а также в популярных репозиториях моделей, таких как Hugging Face, Kaggle и Ollama.
На момент запуска Google заявляет о поддержке с первого дня более десятка фреймворков для инференса, включая vLLM, SGLang, Llama.cpp и MLX, чтобы назвать лишь несколько. ®
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Tobias Mann



