
Китайская технологическая компания Meituan выпустила свою мультимодальную большую модель LongCat-Next, предназначенную для обработки текста, изображений и аудио в рамках единой архитектуры.

Модель построена на архитектуре mixture-of-experts (MoE) LongCat-Flash-Lite и насчитывает в общей сложности 68,5 миллиарда параметров, из которых около 3 миллиардов активируются во время инференса.
Технически LongCat-Next использует парадигму дискретного нативного авторегрессионного подхода (DiNA), преобразуя изображения и аудио в дискретные токены, которые разделяют общее пространство представлений с текстом, что обеспечивает унифицированное кросс-модальное моделирование. Для снижения потерь информации при визуальной токенизации модель включает визуальный токенизатор dNaViT и квантование остаточного вектора (RVQ), что повышает семантическую точность при сохранении поддержки входных данных нативного разрешения.

В публичных бенчмарках LongCat-Next демонстрирует производительность, близкую к моделям с непрерывными признаками в таких задачах, как оптическое распознавание символов (OCR) и понимание сложных диаграмм, а также достигает результатов, сопоставимых с аналогичной по размеру моделью для зрения и языка Qwen3-VL-A3B.
Для задач генерации модель поддерживает синтез изображений и рендеринг текста, выдавая результаты, приближающиеся к показателям специализированных моделей преобразования текста в изображение, таких как Flux-dev, при этом допуская произвольное разрешение выходных данных. В области аудио она поддерживает распознавание, понимание и синтез речи в различных сценариях, демонстрируя устойчивость к диалектам и шумной обстановке.
Экспериментальные результаты показывают, что при единой авторегрессионной цели обучения не возникает существенных компромиссов в производительности между задачами понимания и генерации, а совместное обучение даже улучшает качество генерации. Модель также обеспечивает совместное представление между модальностями через унифицированное пространство токенов.
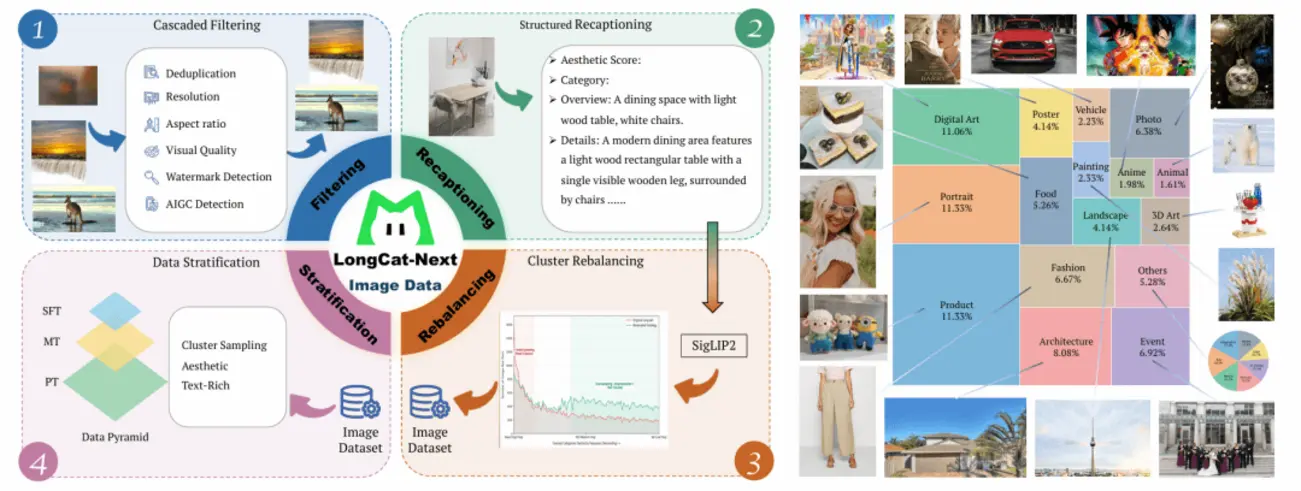
На системном уровне команда использует стратегию планирования V-Half для оптимизации распределения мультимодальной рабочей нагрузки, а также механизмы перебалансировки данных и фильтрации последовательностей для повышения стабильности обучения.
LongCat-Next пока остается на стадии исследования. Команда планирует дальнейшее изучение точности информации при более высоких коэффициентах сжатия, а также стабильности и управляемости в сложных мультимодальных взаимодействиях.
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Pandaily



