
Бум генеративного ИИ взвинтил стоимость памяти до небес, и Google является ключевым участником этой тенденции. Поэтому вполне логично, что Google должна предложить менее требовательные к оперативной памяти локальные модели ИИ. Компания объявила о выпуске новой модели Gemma 4, которая заполняет пробел в линейке, запущенной ранее в этом году. Новая модель достаточно эффективна, чтобы ее можно было запускать на вполне обычном потребительском ноутбуке.
В апреле Google выпустила четыре модели в семействе Gemma 4, что также ознаменовало переход на более открытую лицензию Apache 2.0. Первоначальные модели включали два варианта, оптимизированных для мобильных устройств (E2B и E4B), а также пару моделей для более серьезной работы (26B Mixture of Experts и 31B Dense). Это оставило довольно большой незанятый сегмент посередине, куда как раз и попадает новая модель.
Gemma 4 12B значительно превосходит по возможностям мобильные версии, но для локального запуска ей не потребуется ИИ-ускоритель стоимостью 20 000 долларов. Google заявляет, что Gemma 4 12B уникальна тем, что может работать на многих потребительских ноутбуках без ущерба для качества. При наличии компьютера с 16 ГБ системной ОЗУ или видеопамяти 12-миллиардная модель будет работать. Это примерно половина общего объема памяти Gemma 4 26B MoE, и Google утверждает, что новая модель почти так же производительна, по крайней мере, судя по бенчмаркам.
,
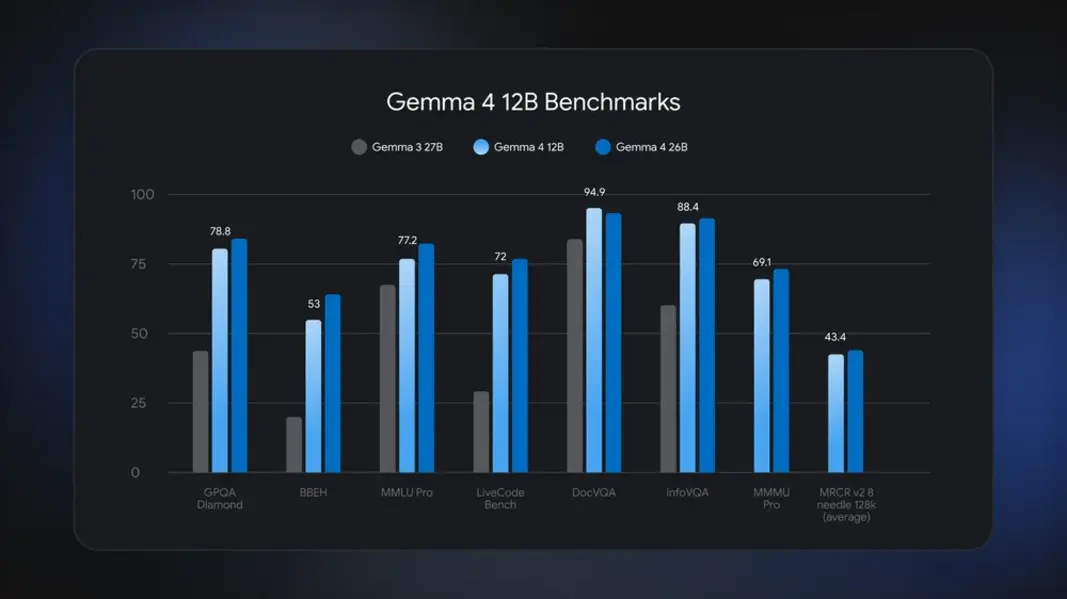
Google заявляет, что новая модель способна выполнять сложные многоэтапные рассуждения и агентурные рабочие процессы, которые ранее требовали более крупных вариантов Gemma. Несмотря на меньшее количество параметров, Gemma 4 12B поставляется с недавно разработанными драфтерами Multi-Token Prediction (MTP), которые используют незадействованные циклы обработки для вычисления возможных будущих токенов. Результатом является повышение скорости и эффективности. Google выпустила необязательные версии MTP для других моделей Gemma 4, но эта первая, в которой MTP реализована изначально.
Gemma 4 12B также более эффективна благодаря новому подходу к мультимодальности. Семейство Gemma 4 изначально мультимодально и принимает в качестве входных данных текст, аудио или изображения. Большинство моделей генеративного ИИ, включая другие варианты Gemma 4, используют выделенные кодировщики для обработки нетекстовых входов и передачи этих данных в LLM. Это работает достаточно хорошо, но увеличивает задержку и потребление памяти.
В новой средневесной модели Google внедрила оптимизированный модуль встраивания для зрения, использующий одноматричное умножение и позиционное встраивание, что позволяет данным передаваться в LLM с надлежащим пространственным осознанием. Это устраняет необходимость в громоздком промежуточном кодировщике. Для аудио кодирование вообще отсутствует. Разработчики нашли способ проецировать необработанный аудиосигнал в те же векторы, которые используются для текстовых токенов.
Если вы хотите ознакомиться с новой моделью Gemma 4, она доступна без загрузки через такие инструменты, как LM Studio, Google AI Edge Gallery и другие. Но вся идея Gemma 4 12B заключается в том, что вы можете запускать ее локально и на своих условиях. Если у вас достаточно ОЗУ, веса модели доступны для немедленной загрузки на Kaggle и Hugging Face. Это чуть меньше 18 ГБ.
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Ryan Whitwam



