
Вышел DeepSeek V4, который принес серьезные оптимизации, включая модели размером до 1,6 трлн параметров, а NVIDIA уже готова к поддержке “нулевого дня” на графических процессорах Blackwell с использованием NVFP4.
Архитектура NVIDIA Blackwell NVFP4 Обеспечивает Значительный Рост Скорости в DeepSeek v4, Ожидаются Дальнейшие Оптимизации
С запуском DeepSeek V4 мы увидели серьезные оптимизации в требованиях к вычислениям и памяти.
Обновленная модель ИИ использует всего 27% от FLOPs для инференса одного токена и 10% от KV-кэша при работе с контекстным окном в один миллион токенов. Были представлены две новые модели: Pro с 1,6 трлн параметров и Flash-версия с 284 млрд параметров.
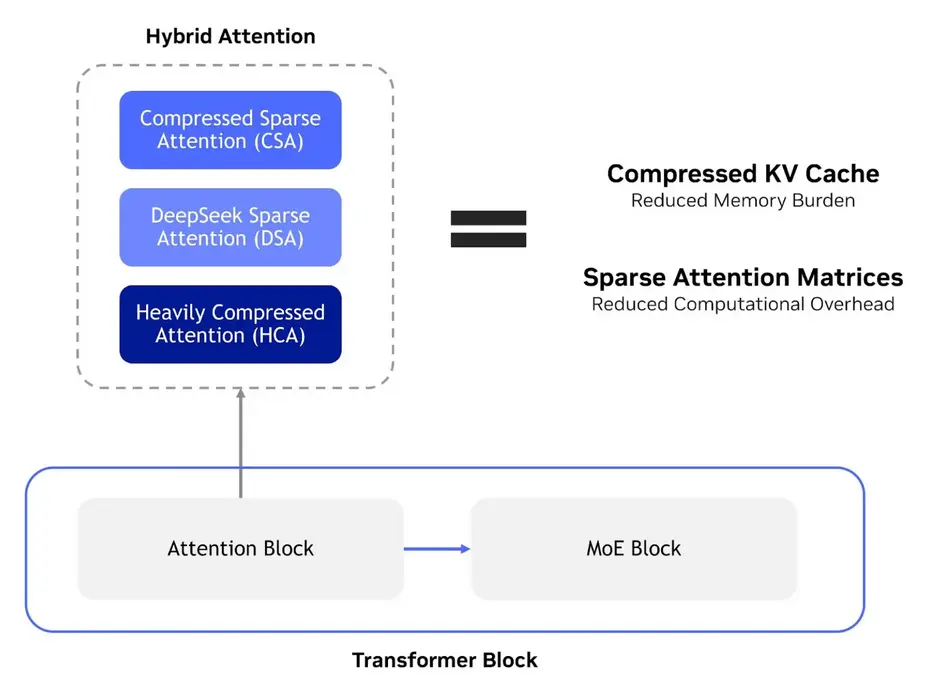
Этим запуском NVIDIA демонстрирует поддержку “нулевого дня” и производительность графических процессоров Blackwell в DeepSeek V4. Компания заявляет, что GPU Blackwell обеспечивают необходимый масштаб и низколатентную производительность для запуска инференса с длинным контекстом в 1 млн токенов и триллионных моделей ИИ, которые предлагает V4.
От развертываний в центрах обработки данных на NVIDIA Blackwell до управляемых микросервисов NIM и рабочих процессов тонкой настройки — NVIDIA предлагает ряд вариантов для интеграции DeepSeek и других открытых моделей на разных этапах разработки и развертывания. NVIDIA является активным участником экосистемы с открытым исходным кодом и выпустила несколько сотен проектов под лицензиями с открытым исходным кодом. NVIDIA стремится оптимизировать программное обеспечение сообщества и открытые модели, позволяя пользователям широко обмениваться результатами работы в области безопасности и устойчивости ИИ.
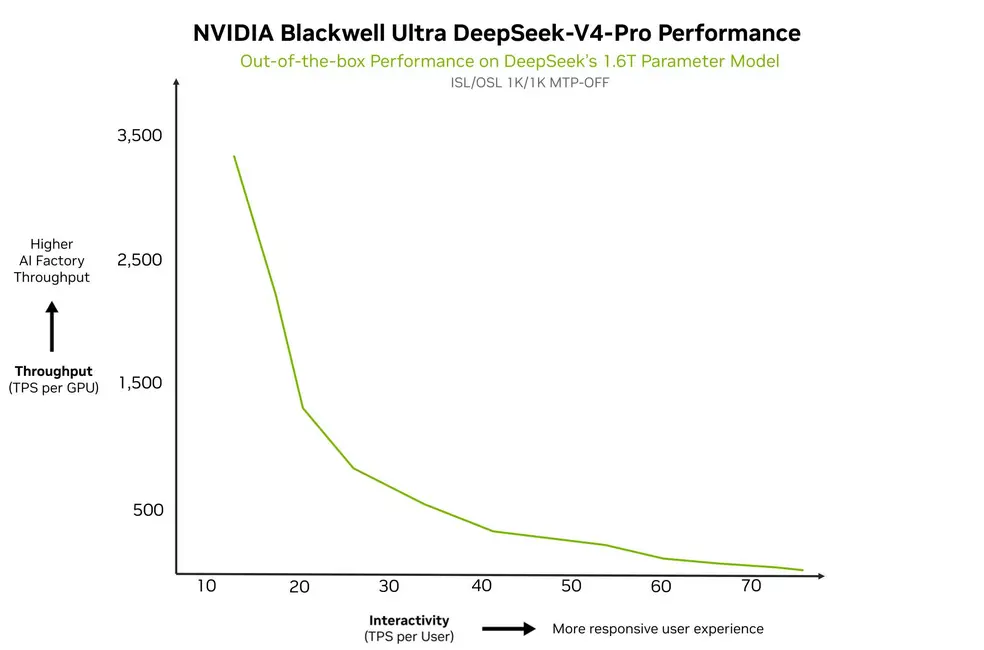
На слайде с производительностью NVIDIA демонстрирует пропускную способность почти 3500 TPS на один графический процессор (GB300 или Blackwell Ultra), и это лишь предварительные цифры, которые, как ожидается, вырастут по мере внесения дальнейших оптимизаций в стек совместного проектирования. Стек NVIDIA Blackwell предлагает ряд технологий, специально разработанных для таких моделей, как V4, включая NVFP4, Dynamo, оптимизированные ядра CUDA, передовые методы параллелизации и многое другое.
Ключевым моментом для DeepSeek V4 является применение квантования FP4 (MXFP4), которое используется для ускорения как развертывания, так и проходов инференса. Благодаря FP4 DeepSeek, модели V4 снижают трафик памяти и задержку сэмплирования.
Следует отметить, что новейшие чипы Huawei Ascend, Ascend 950PR и Ascend 950DT, запланированные на 2026 год, будут включать инструкции MXFP4. Это показывает, что DeepSeek V4 также будет полностью совместим с отечественными китайскими ИИ-чипами.
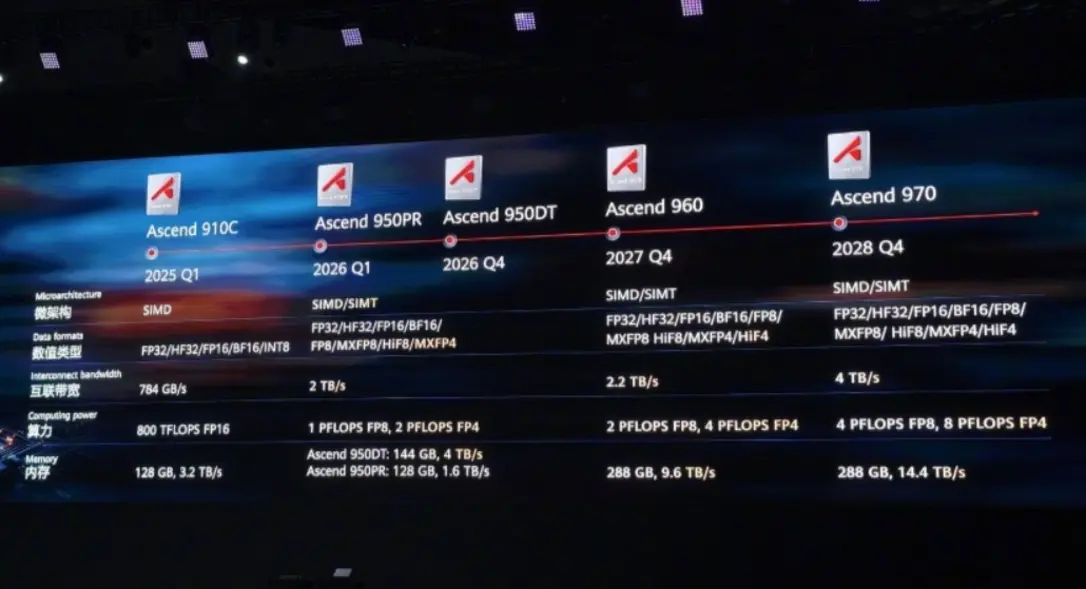
Благодаря постоянным оптимизациям NVIDIA, будущие модели получат надежную поддержку экосистемы “из коробки”.
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Hassan Mujtaba



