
22 января 2026 года — Команда Qwen от Alibaba официально представила в открытый доступ полную серию моделей преобразования текста в речь Qwen3-TTS, включающую модели с многокодовыми речевыми представлениями в двух размерах: 1,7 миллиарда параметров для максимальной производительности и 0,6 миллиарда параметров, оптимизированных для баланса качества и эффективности. Модели теперь доступны на GitHub, ModelScope и других платформах, при этом живой доступ поддерживается через API Qwen.
Qwen3-TTS предлагает всеобъемлющий набор функций, включая клонирование голоса, генерацию голоса, синтез речи, максимально приближенный к человеческому, и управление синтезом с помощью инструкций на естественном языке. Благодаря саморазработанному 12-герцовому энкодеру речи с многокодовым представлением Qwen3-TTS-Tokenizer-12Hz, модель сохраняет богатые паралингвистические сигналы и детали акустической среды, обеспечивая высокоточную реконструкцию голоса.
Ключевым нововведением является архитектура моделирования с двумя треками (Dual-Track), которая сокращает задержку сквозного синтеза всего до 97 миллисекунд, при этом первый аудиопакет генерируется после обработки одного символа, что делает решение идеально подходящим для приложений, требующих диалогового взаимодействия в реальном времени.
Модель поддерживает 10 основных языков, включая китайский, английский, японский и немецкий, а также множество диалектов. Она способна автоматически адаптировать интонацию, ритм и эмоциональную окраску в зависимости от семантического контекста, демонстрируя при этом высокую устойчивость к зашумленному или неточному текстовому вводу. По результатам множества тестов Qwen3-TTS показывает передовые результаты: её возможности по генерации голоса превосходят MiniMax-Voice-Design, её кросс-языковое клонирование голоса опережает CosyVoice3, а при генерации длинных речевых фрагментов достигается частота ошибок (WER) всего 2,36% (китайский) и 2,81% (английский).
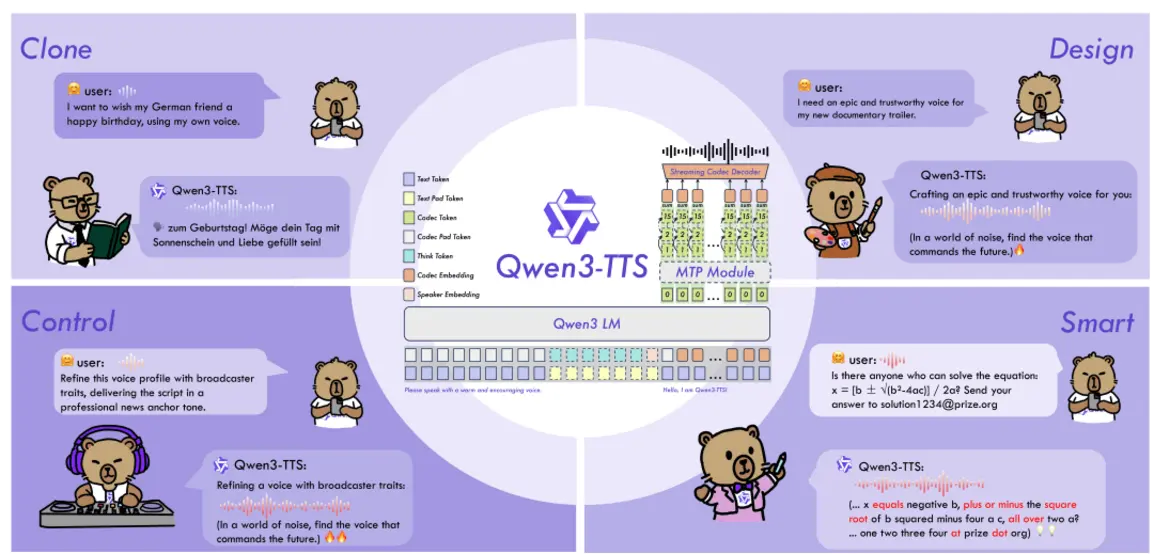
Сочетая многоязычную поддержку, сверхнизкую задержку и высокое качество звука, Qwen3-TTS предлагает эффективное и масштабируемое решение для глобального голосового взаимодействия и речевых приложений реального времени.
-
ModelScope: https://www.modelscope.cn/collections/Qwen/Qwen3-TTS
-
Hugging Face: https://huggingface.co/collections/Qwen/qwen3-tts
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Pandaily



