
Компания Apple наконец-то представила CoreAI — преемника своего движка CoreML, который доминировал на рынке около 9 лет. Новинка предлагает инференс, не зависящий от формата, и поддержку больших объемов памяти для моделей. Тем не менее, первые тесты рисуют гораздо более неоднозначную картину нового фреймворка Apple для ИИ и, соответственно, его моделей для работы на устройствах.
Новые тесты производительности показывают, что CoreAI от Apple «сходится к ничьей с MLX» при реалистичном размере модели 8B для декодирования
Для тех, кто, возможно, не в курсе, Apple выпустила свой фреймворк машинного обучения CoreML в 2017 году, предназначенный в первую очередь для выполнения небольших статических задач машинного обучения, таких как классификация изображений и древовидные ансамбли. CoreAI — это совершенно новый преемник CoreML, оптимизированный для периферийного ИИ и инференса на устройствах.
В отличие от него, MLX — это движок, ориентированный в первую очередь на исследования, обучение и тонкую настройку, и он привязан к GPU Meta*l от Apple и архитектуре унифицированной памяти.
Недавно новый тест производительности дал нам интересное представление о новом движке CoreAI от Apple.
Во-первых, для небольших моделей, таких как Qwen3 с 0,6 миллиарда параметров, CoreAI примерно в 2,47 раза быстрее MLX при выполнении задач декодирования на Mac с чипом M4. Аналогично, на iPhone 17 Pro CoreAI примерно в 1,6 раза быстрее MLX при декодировании, опять же на основе модели Qwen3 0.6b. Однако при увеличении размера модели до более практичных 8 миллиардов параметров (Qwen3 8b, M4 Max Mac) CoreAI лишь на 1,05x быстрее MLX и демонстрирует почти паритетную производительность декодирования.
Интересно, что при длительных нагрузках на iPhone 17 Pro графический процессор относительно быстро снижает частоту, что позволяет комбинации CoreML/Apple Neural Engine вырваться вперед по сохраняемой производительности. Эта комбинация также потребляет меньше всего памяти, но при этом является самой медленной в задачах декодирования.
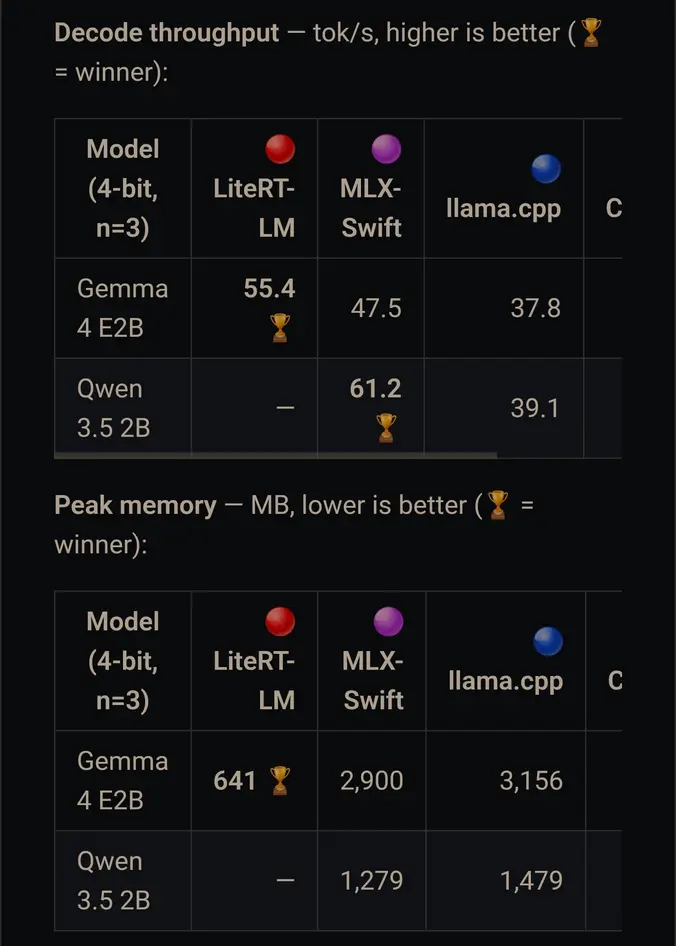
Движки, оптимизированные под конкретные модели от поставщиков, почти всегда превосходят общие движки. Например, движок LiteRT-LM от Google, работающий с моделью Gemma, не только оказался самым быстрым движком на iPhone 17 Pro (55,4 токена в секунду), но и использовал в 4,5 раза меньше оперативной памяти, чем собственный фреймворк Apple MLX (641 МБ против 2900 МБ).
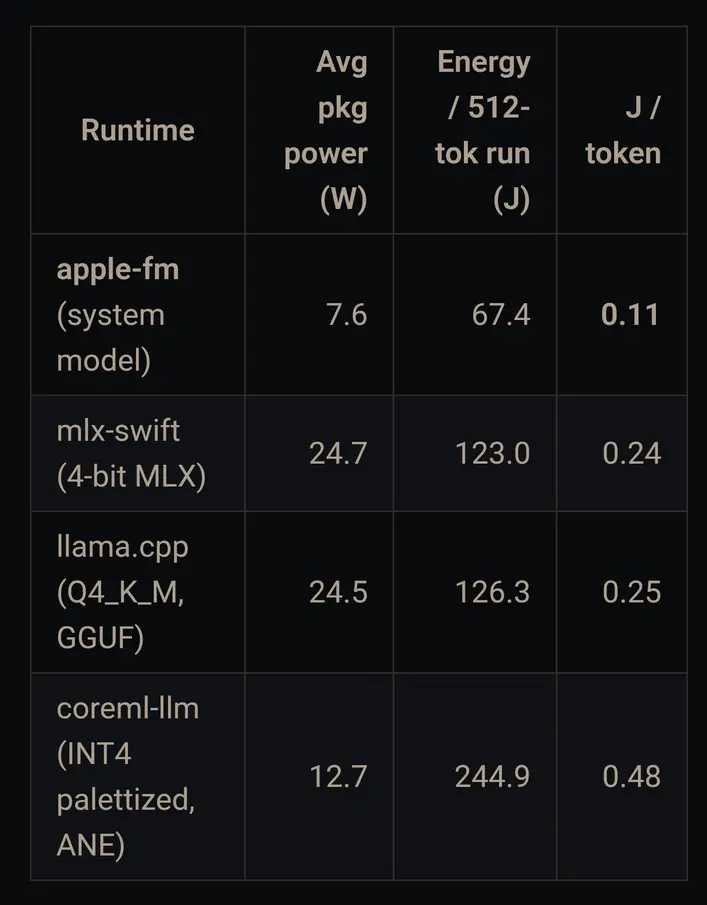
Наконец, было обнаружено, что модели Apple Foundation «в 2 раза более энергоэффективны на токен, чем среды выполнения на базе GPU, и в 4 раза более энергоэффективны, чем CoreML/ANE».
Facebook*, Instagram* и WhatsApp* принадлежат компании Meta* Platforms Inc., деятельность которой признана экстремистской и запрещена на территории Российской Федерации.
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Rohail Saleem



