
На конференции GDC 2026 инженер по графике Intel Марисса Дюбуа вышла на сцену, чтобы представить версию Intel по нейронному сжатию текстур, очень похожую на NTC от NVIDIA тем, что обе технологии детерминированы. Презентация стала продолжением оригинального прототипа НИОКР, показанного на GDC 2025, а главная новость заключается в том, что Intel теперь превратила это исследование в отдельный SDK.
Нейронное сжатие наборов текстур (Texture Set Neural Compression, TSNC) — это, по сути, более интеллектуальный способ хранения игровых текстур. Традиционные форматы блочного сжатия GPU (от BC1 до BC7) используют фиксированные математические правила для уменьшения размера текстуры, и хотя они быстры и универсально поддерживаются, они оставляют значительный потенциал сжатия неиспользованным. TSNC использует принципиально иной подход: он обучает небольшую нейронную сеть с помощью стохастического градиентного спуска, чтобы научиться кодировать и декодировать специфические текстуры в заданном наборе. Результатом является компактное представление в латентном пространстве, которое крошечный многослойный перцептрон может реконструировать во время выполнения в исходные диффузные данные, карты нормалей, шероховатости, металличности, затенения окружающей среды и эмиссионные данные.
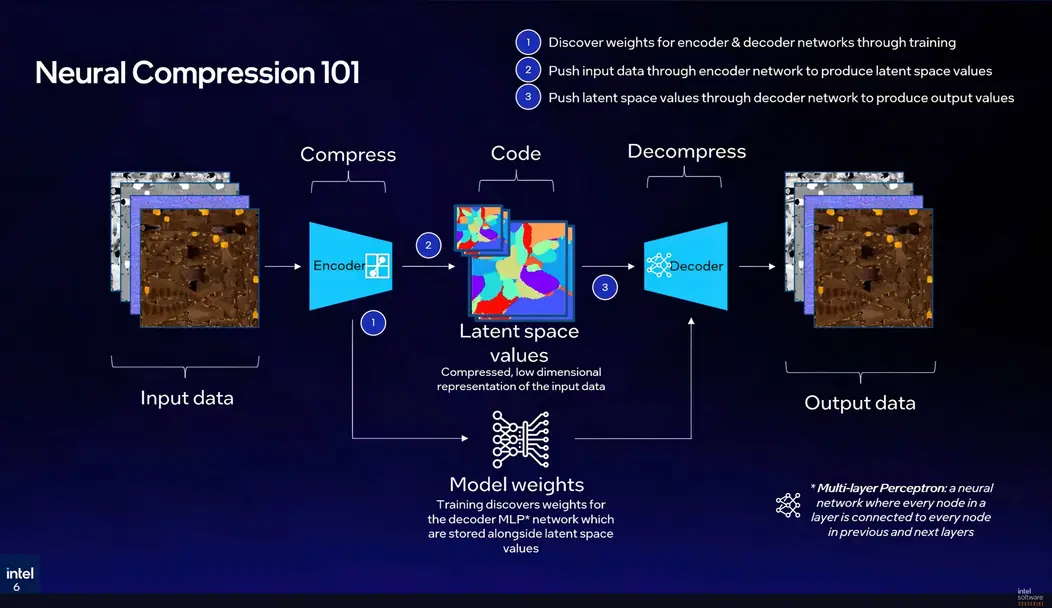
Ключевое понимание состоит в том, что набор текстур (все PBR-карты для одного материала) имеет много избыточной структуры в своих каналах. TSNC использует эту общую структуру способами, которые просто недоступны для общего блочного сжатия.
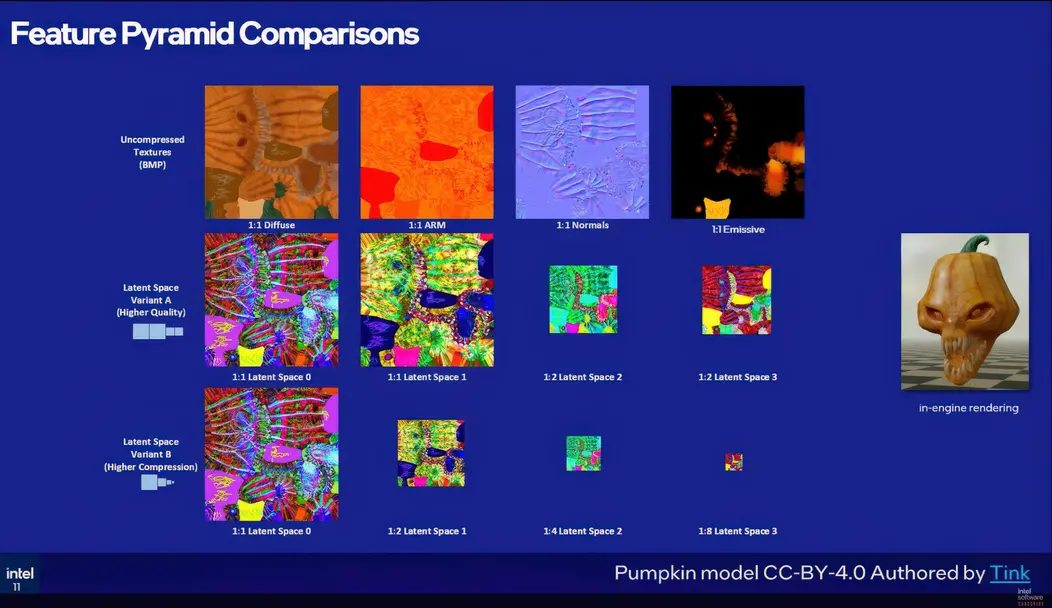
Пирамиды признаков: два уровня
В основе схемы сжатия TSNC лежит пирамида признаков — набор из четырех текстур латентного пространства, закодированных в BC1 и расположенных в разных конфигурациях разрешения. В настоящее время Intel предлагает два варианта с различными компромиссами между качеством и степенью сжатия:
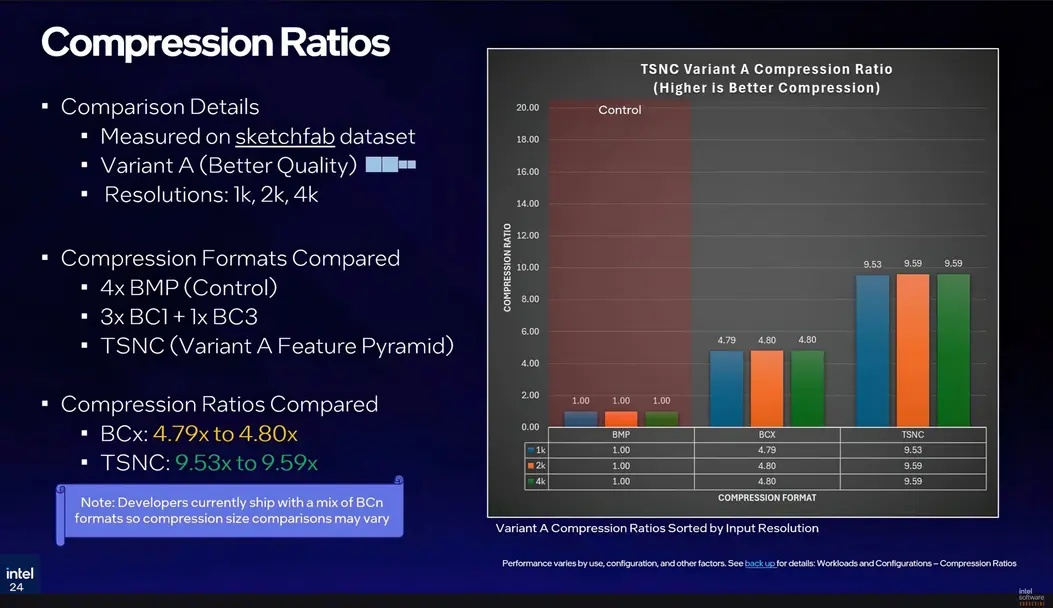
- Вариант A использует два изображения латентного пространства полного разрешения и два изображения половинного разрешения. Для входных 4K-текстур это означает две 4K и две 2K латентные картинки, что в сумме составляет около 26,8 МБ по сравнению с исходными 256 МБ несжатых растровых изображений. Это дает сжатие более чем в 9 раз, что почти вдвое превышает 4,8-кратное сжатие, которое можно получить только от стандартного блочного сжатия BC. Потеря воспринимаемого качества, измеренная с помощью инструмента анализа FLIP от NVIDIA, составляет около 5%, что на практике проявляется как незначительная потеря точности в картах нормалей, но ни в чем другом.
- Вариант B — агрессивный вариант. Он каскадирует латентные изображения до 1/2, 1/4 и 1/8 исходного разрешения, достигая сжатия более чем в 17 раз, что более чем вдвое превышает показатель Варианта A. Однако потеря качества более заметна: артефакты блочного сжатия BC1 начинают появляться на картах нормалей и каналах AO/шероховатости, а FLIP фиксирует воспринимаемую ошибку на уровне 6–7%. В абсолютных величинах это может показаться немного, но Intel признает, что это «достаточно, чтобы быть заметным для наблюдателя». Таким образом, Вариант B, вероятно, лучше всего подходит для удаленных или второстепенных материалов, где потеря качества вряд ли будет подвергаться пристальному изучению.
С момента появления прошлогоднего прототипа НИОКР, изначально созданного на PyTorch, весь компрессор Texture Set Neural Compression был полностью переписан с использованием шейдеров вычислений Slang. Кроме того, независимо от того, работает ли разработчик в Unreal, использует ли собственный движок или выполняет декомпрессию на ЦП, один и тот же код декомпрессора может быть нацелен на нужный бэкенд.
На стороне ГП Intel теперь поддерживает API Cooperative Vectors от Microsoft DirectX 12, используя матричные ядра XMX от Intel Arc (присутствующие как в графических процессорах серии A, так и серии B) для аппаратно-ускоренного матричного вывода. Для оборудования без поддержки XMX стандартный запасной вариант FMA (fused multiply-and-add) работает как на ЦП, так и на не-Intel ГП.
Марисса Дюбуа из Intel описала четыре различные стратегии развертывания, каждая из которых имеет разный компромисс между экономией дискового пространства и использованием памяти:
- Во время установки — поставлять сжатые данные, распаковывать локально во время установки. Текстуры остаются несжатыми на диске пользователя. Экономия в основном достигается за счет пропускной способности при распространении.
- Во время загрузки — текстуры остаются сжатыми на диске; декомпрессия происходит в VRAM по мере загрузки игры. Уменьшает как размер установки, так и давление на VRAM во время загрузки.
- Во время потоковой передачи — в сочетании с потоковой передачей текстур декомпрессия происходит по требованию. Лучшее из обоих миров для диска и памяти, но добавляет нагрузку на вывод во время выполнения.
- Во время выборки — текстуры остаются сжатыми в VRAM постоянно и декодируются попиксельно в шейдере. Самый агрессивный вариант для уменьшения VRAM с постоянной стоимостью вывода.
Разработчикам придется выбирать один из вариантов в зависимости от их конкретного сценария использования и базового движка.
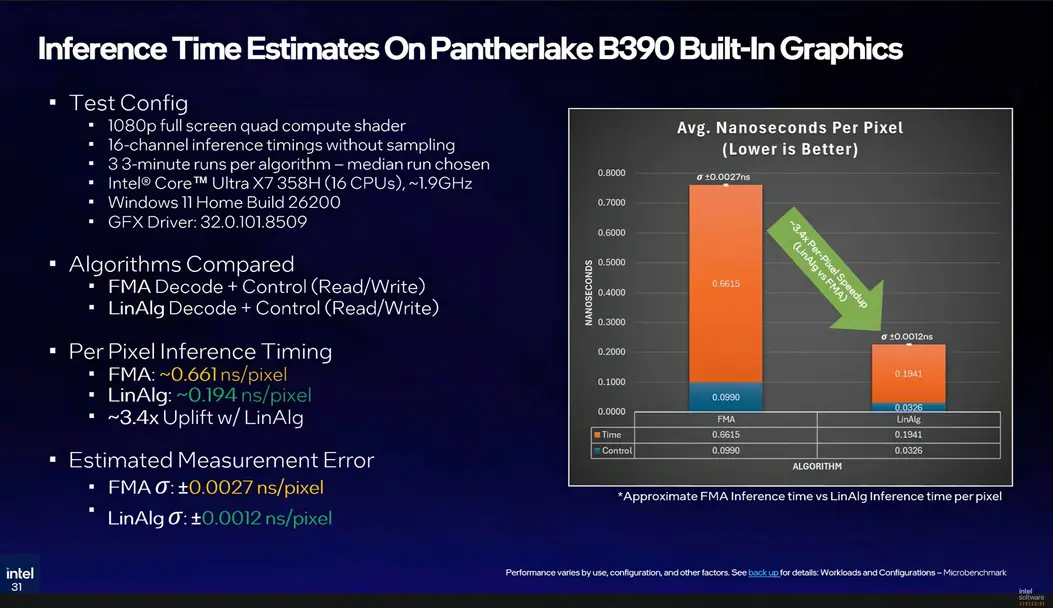
Intel провела эталонные тесты вывода на ноутбуке Panther Lake с интегрированной графикой B390 при полной нагрузке шейдера вычислений 1080p. Результаты были следующими:
- Путь FMA: 0,661 наносекунды на пиксель
- Путь линейной алгебры XMX: 0,194 наносекунды на пиксель
Это ускорение в 3,4 раза благодаря аппаратно-ускоренной матричной математике, и тот факт, что эти цифры сохраняются на интегрированной графике, делает сценарий развертывания попиксельной выборки более жизнеспособным, чем могло показаться. Для дискретных ГП накладные расходы будут еще ниже. Intel планирует выпустить альфа-версию SDK Texture Set Neural Compression позднее в этом году, за которой последуют бета-версия и публичный релиз, хотя эти даты еще не утверждены.
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Alessio Palumbo



