
NVIDIA планирует доминировать в стеке логического вывода с помощью чипов Feynman следующего поколения, поскольку компания может интегрировать блоки LPU в архитектуру.
NVIDIA может использовать гибридную склейку с кристаллами SRAM для логического вывода, но есть несколько последствий
Соглашение Team Green о лицензировании IP-адресов для блоков LPU от Groq может показаться умеренным событием, если смотреть на масштабы приобретения и связанные с этим доходы, но на самом деле NVIDIA намерена занять лидирующие позиции в сегменте логического вывода с помощью LPU, и мы уже обсуждали это в обширном материале. Что касается того, как NVIDIA планирует интегрировать LPU, то было предложено несколько вариантов, однако, основываясь на том, что считает эксперт по GPU AGF, похоже, что блоки LPU могут быть установлены на графических процессорах Feynman следующего поколения с помощью технологии гибридной склейки TSMC.
Эксперт считает, что реализация может напоминать то, что AMD сделала с процессорами X3D, используя технологию гибридной склейки SoIC от TSMC для интеграции 3D V-Cache на основной вычислительный кристалл. AGF утверждает, что интеграция SRAM в качестве монолитного кристалла может быть неверным шагом для графических процессоров Feynman, учитывая, что масштабирование SRAM ограничено, а создание его на передовых узлах приведет к потере высококачественного кремния и резкому увеличению стоимости использования на единицу площади пластины. Вместо этого AGF считает, что NVIDIA будет устанавливать блоки LPU на вычислительный кристалл Feynman.
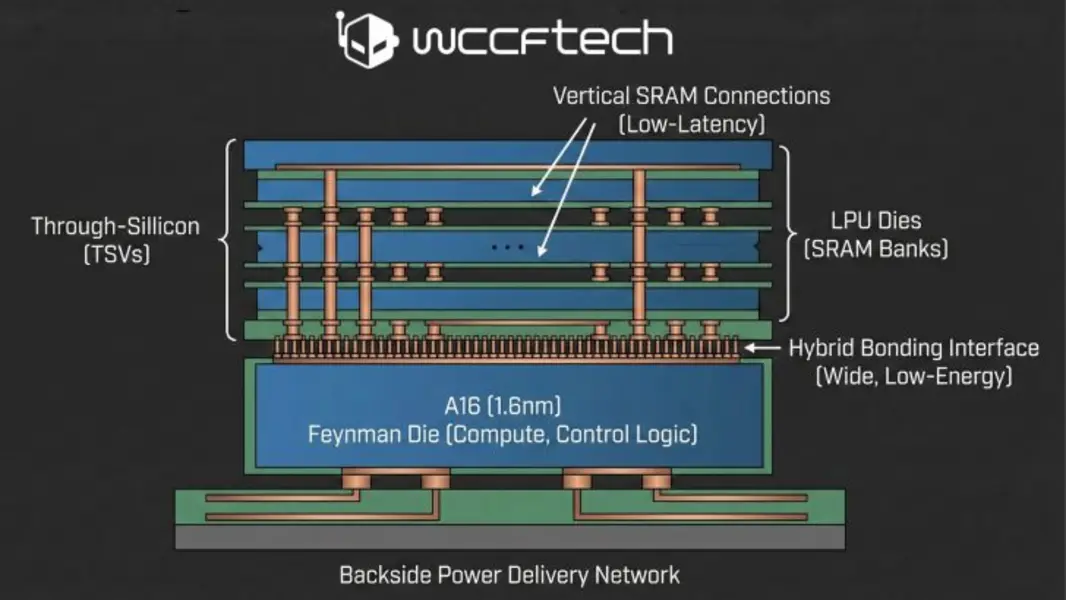
Теперь такой подход кажется разумным, учитывая, что при этом такие чипы, как A16 (1,6 нм), будут использоваться для основного кристалла Feynman, который содержит вычислительные блоки (тензорные блоки, логику управления и т. д.), в то время как отдельные кристаллы LPU будут содержать большие банки SRAM. Кроме того, для соединения этих кристаллов технология гибридной склейки TSMC окажется решающей, поскольку она обеспечит широкий интерфейс и меньшее энергопотребление на бит по сравнению с внешней памятью. В довершение ко всему, поскольку A16 имеет систему подачи питания с обратной стороны, передняя сторона будет освобождена для вертикальных соединений SRAM, что обеспечит низкую задержку ответа декодирования.
Однако при использовании этого метода возникают опасения относительно того, как NVIDIA будет управлять тепловыми ограничениями, поскольку установка кристаллов на процесс, который работает с высокой плотностью вычислений, уже является проблемой. А с LPU, которые ориентированы на устойчивую пропускную способность, это может создать узкие места. Что еще более важно, последствия на уровне исполнения также значительно возрастут при таком подходе, поскольку LPU концентрируются на фиксированном порядке исполнения, что, конечно, создает конфликт между детерминизмом и гибкостью.

Даже если NVIDIA удастся разрешить аппаратные ограничения, основная проблема вызвана тем, как CUDA ведет себя при выполнении в стиле LPU, поскольку она требует явного размещения памяти, тогда как ядра CUDA предназначены для аппаратной абстракции. Интеграция SRAM в архитектуры AI не будет простой задачей для Team Green, поскольку потребуется инженерное чудо, чтобы обеспечить хорошую оптимизацию сред LPU-GPU. Однако это может быть ценой, которую NVIDIA готова заплатить, если хочет лидировать в сегменте логического вывода.
Всегда имейте в виду, что редакции некоторых изданий могут придерживаться предвзятых взглядов в освещении новостей.
7/8
Автор – Muhammad Zuhair




{kind=link}