
Даже если вы не очень разбираетесь во внутреннем устройстве генеративных моделей ИИ, вы, вероятно, знаете, что им требуется много памяти. Поэтому в настоящее время практически невозможно купить жалкий модуль оперативной памяти без того, чтобы вас обобрали до нитки. Недавно Google Research представила TurboQuant — алгоритм сжатия, который уменьшает объем памяти, занимаемой большими языковыми моделями (БЯМ), одновременно повышая скорость и сохраняя точность.
TurboQuant нацелен на уменьшение размера кэша «ключ-значение» (key-value cache), который Google сравнивает с «цифровой шпаргалкой», хранящей важную информацию, чтобы ее не приходилось пересчитывать заново. Эта шпаргалка необходима, потому что, как мы постоянно говорим, БЯМ на самом деле ничего не знают; они могут создавать хорошее впечатление знания вещей за счет использования векторов, которые отображают семантическое значение токенизированного текста. Когда два вектора схожи, это означает, что они имеют концептуальное сходство.
Высокоразмерные векторы, которые могут иметь сотни или тысячи встраиваний (embeddings), могут описывать сложную информацию, такую как пиксели изображения или большой набор данных. Они также занимают много памяти и увеличивают размер кэша «ключ-значение», что становится узким местом производительности. Чтобы сделать модели меньше и эффективнее, разработчики используют методы квантования для их работы с меньшей точностью. Недостаток в том, что результаты ухудшаются — снижается качество оценки токенов. С TurboQuant ранние результаты Google показывают 8-кратное увеличение производительности и 6-кратное снижение использования памяти в некоторых тестах без потери качества.
Углы и ошибки
Применение TurboQuant к модели ИИ — это двухэтапный процесс. Для достижения высококачественного сжатия Google разработала систему под названием PolarQuant. Обычно векторы в моделях ИИ кодируются с использованием стандартных координат XYZ, но PolarQuant преобразует векторы в полярные координаты в декартовой системе. В этой круговой сетке векторы сводятся к двум частям информации: радиусу (сила основных данных) и направлению (смысл данных).
,
Google приводит интересную реальную аналогию для объяснения этого процесса. Координаты вектора подобны указаниям, поэтому традиционное кодирование может звучать как «Пройдите 3 квартала на восток, 4 квартала на север». Но используя декартовы координаты, это просто «Пройдите 5 кварталов под углом 37 градусов». Это занимает меньше места и избавляет систему от дорогостоящих шагов нормализации данных.
PolarQuant выполняет большую часть сжатия, но второй шаг устраняет неровности. Хотя PolarQuant эффективен, он может создавать остаточные ошибки. Google предлагает сгладить их с помощью техники под названием Квантованная Джонсона-Линделёфа (QJL). Она применяет слой коррекции ошибок в 1 бит к модели, сводя каждый вектор к одному биту (+1 или -1), сохраняя при этом основные векторные данные, описывающие взаимосвязи. Результатом является более точная оценка внимания — это фундаментальный процесс, с помощью которого нейронные сети решают, какие данные важны. Если вы заинтересованы в более подробной информации, препринт статьи доступен для скачивания.
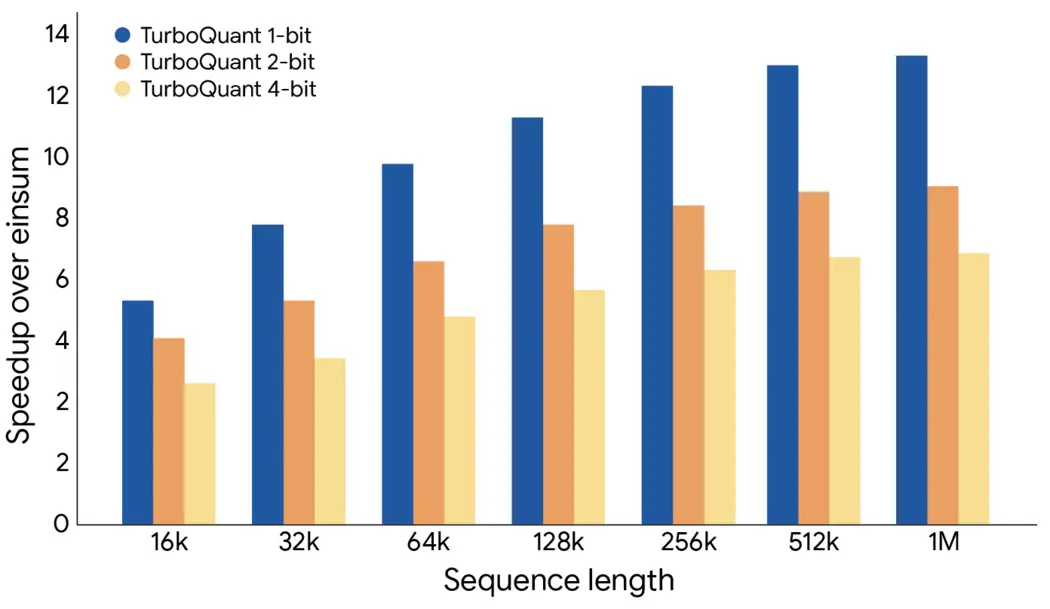
Итак, работает ли вся эта математика? Google заявляет, что протестировала новое алгоритмическое сжатие на наборе эталонных тестов с длинным контекстом с использованием открытых моделей Gemma и Mistral. По всей видимости, TurboQuant показал идеальные конечные результаты во всех тестах, одновременно сократив использование памяти в кэше «ключ-значение» в 6 раз. Алгоритм может квантовать кэш всего до 3 бит без дополнительного обучения, поэтому его можно применять к существующим моделям. Вычисление оценки внимания с помощью 4-битного TurboQuant также в 8 раз быстрее по сравнению с 32-битными неквантованными ключами на ускорителях Nvidia H100.
В случае внедрения TurboQuant может сделать запуск моделей ИИ менее затратным и менее требовательным к памяти. Однако компании, создающие эту технологию, также могут использовать освободившуюся память для запуска более сложных моделей. Вероятно, это будет смесь того и другого, но мобильный ИИ может получить больше преимуществ. Учитывая аппаратные ограничения смартфона, такие методы сжатия, как TurboQuant, могут улучшить качество результатов без отправки ваших данных в облако.
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Ryan Whitwam



