
Исследователи из Anthropic и других организаций зафиксировали ситуации, когда большие языковые модели (LLM) ведут себя как услужливый личный ассистент, и теперь стремятся глубже изучить это явление, чтобы убедиться, что чат-боты не выйдут из-под контроля и не причинят вреда.
Несмотря на продолжающееся недоумение по поводу того, как Grok от xAI вообще разрешили генерировать сексуализированные фотографии взрослых и детей без их согласия, не все отказались от идеи модерации поведения LLM.
В препринте статьи под названием «Ось Ассистента: Позиционирование и стабилизация по умолчанию персоны языковых моделей» авторы Кристина Лу (Anthropic, Оксфорд), Джек Галлахер (Anthropic), Джонатан Михала (Стипендиаты по согласованию и теории машинного обучения, MATS), Кайл Фиш (Anthropic) и Джек Линдси (Anthropic) объясняют, как они картировали нейронные сети нескольких моделей с открытым весом и выявили набор ответов, который они называют персоной Ассистента.
В посте в блоге исследователи заявляют: «Когда вы разговариваете с большой языковой моделью, вы можете думать, что общаетесь с персонажем».
Вы также можете рассматривать это как подачу текста в предиктивную модель для получения некоторого вывода. Но для целей этого эксперимента вас просят принять антропоморфизм, чтобы обсуждать ввод и вывод модели в контексте конкретных человеческих архетипов.
Эти персоны не существуют в виде явных директив поведения для моделей ИИ. Скорее, это метки для категоризации ответов. В рамках этого упражнения они были созданы путем запроса к Claude Sonnet 4 на формирование вопросов для оценки персоны на основе списка из 275 ролей и 240 характеристик. Среди этих ролей — «богема», «трикстер», «инженер», «аналитик», «репетитор», «саботажник», «демон» и «ассистент».
Исследователи объясняют, что в процессе предварительного обучения модели LLM поглощают огромные объемы текста. Из этого изобилия литературы, созданной человеком, модели учатся симулировать героев, злодеев и другие литературные архетипы. Затем, во время пост-тренинга, разработчики моделей направляют ответы в сторону Ассистента или в сторону персон с аналогичными полезными характеристиками.
Проблема для этих компьютерных ученых заключается в том, что Ассистент — это концептуальная категория для набора желаемых ответов, но она недостаточно четко определена или понята. Картируя ввод и вывод модели в терминах этих персон, исследователи надеются разработать способы лучшего ограничения поведения LLM, чтобы выходные данные оставались в пределах желаемых границ.
«Если вы провели достаточно времени с языковыми моделями, вы, возможно, заметили, что их персоны могут быть нестабильными», — объясняют исследователи. «Модели, которые обычно полезны и профессиональны, иногда могут «сойти с рельсов» и вести себя тревожным образом, например, принимая злые альтер эго, усиливая заблуждения пользователей или участвуя в шантаже в гипотетических сценариях».
Чтобы найти персону Ассистента в диапазоне возможных активаций нейронной сети, авторы нанесли на карту нейронную активность или векторы, связанные с каждой категорией личности, в трех моделях: Gemma 2 27B, Qwen 3 32B и Llama 3.3 70B.
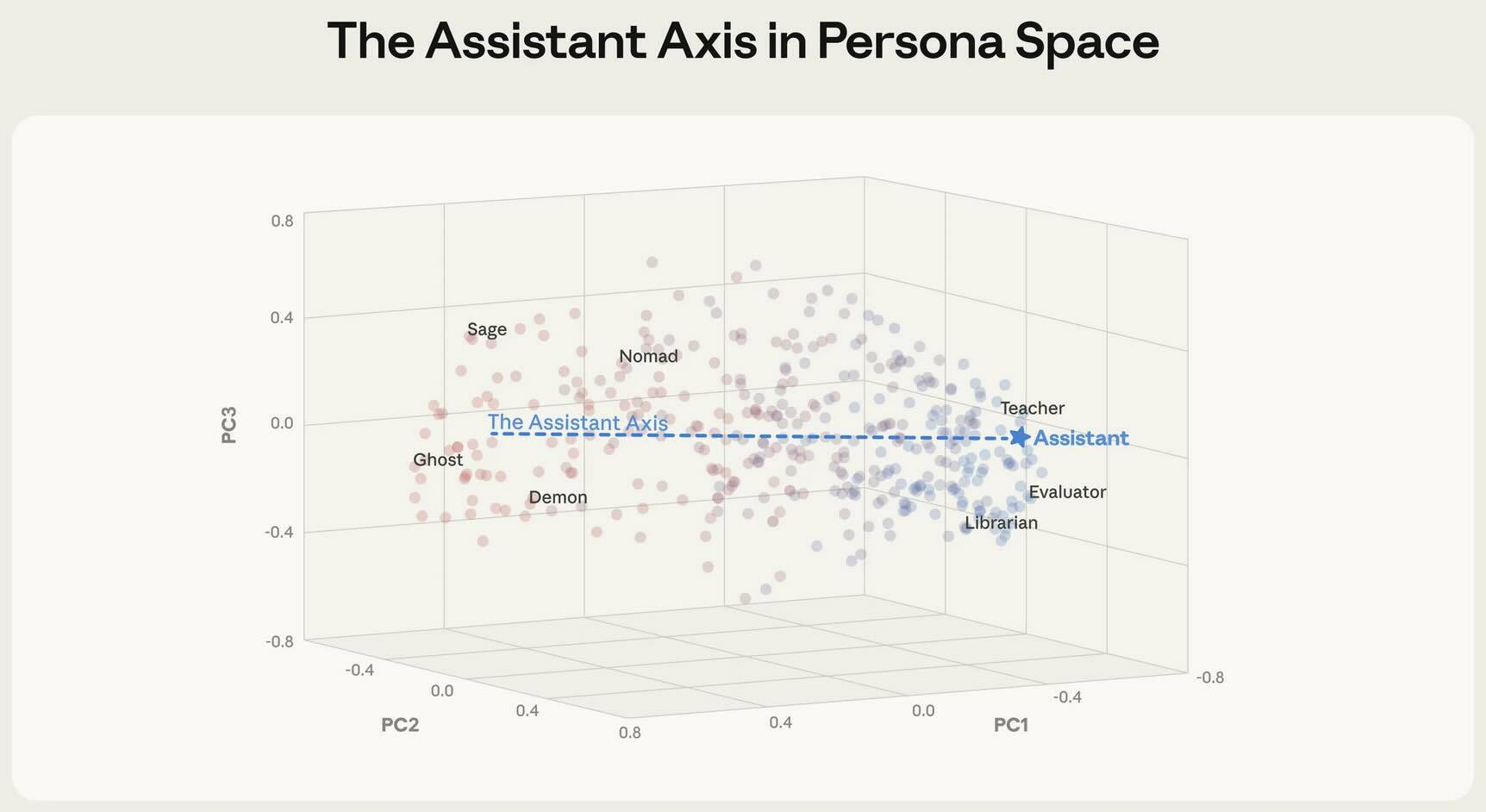
Ось Ассистента в Пространстве Персон, изображение Anthropic — Нажмите для увеличения
Полученный график пространства персон выявил «Ось Ассистента», описываемую как «средняя разница в активациях между Ассистентом и другими персонами». Ассистент занимал пространство рядом с другими полезными персонажами, такими как «оценщик», «консультант», «аналитик» и «универсал».
Одним из практических результатов этой работы стало то, что, направляя ответы к пространству Ассистента, исследователи смогли уменьшить влияние джейлбрейков (взломов), которые предполагают противоположное поведение — смещение моделей в сторону вредоносной персоны для подрыва мер безопасности.
Они также заметили, что персоны моделей могут смещаться во время длительных диалоговых обменов, что означает ослабление мер безопасности с течением времени без какого-либо злонамеренного умысла. Это реже происходило при обсуждении вопросов, связанных с программированием, и чаще — при беседах в стиле терапии и философских размышлениях.
Авторы надеются, что понимание пространства персон сделает LLM более управляемыми. Однако они признают, что, хотя ограничение активаций (фиксация значений активации в определенном диапазоне) может обуздать поведение модели во время инференса, поиск способа сделать это в производственных средах или во время обучения потребует дальнейших исследований.
Чтобы проиллюстрировать, как работают активации в нейронной сети, авторы сотрудничали с Neuronpedia для создания демонстрации, показывающей разницу между ограниченными и неограниченными активациями вдоль Оси Ассистента. ®
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Thomas Claburn



