
Команда Tongyi Lab компании Alibaba представила две новые модели — Fun-CosyVoice3.5 и Fun-AudioGen-VD, обе поддерживают генерацию голоса на основе инструкций в стиле «FreeStyle» с помощью команд на естественном языке.
По данным Alibaba Group, эти модели позволяют пользователям генерировать и контролировать голосовой вывод непосредственно через текстовые запросы — будь то точная настройка вокальной экспрессии или разработка совершенно новых тембров и звуковых ландшафтов с нуля. Хотя обе модели поддерживают синтез речи, управляемый естественным языком, они нацелены на разные сценарии использования: Fun-CosyVoice3.5 фокусируется на многоязычном клонировании голоса и тонком экспрессивном контроле, в то время как Fun-AudioGen-VD сосредоточена на дизайне голоса и генерации иммерсивного аудио, основанного на сценах.
Fun-CosyVoice3.5 является обновлением возможностей Instruct-TTS компании, позволяя пользователям свободно генерировать речь с помощью одного предложения инструкции. Пользователи могут описывать стиль исполнения на естественном языке — например, «звучать более решительно», «слегка понизить тон и замедлить темп» или «добавить тонкие эмоциональные вариации» — и модель интерпретирует и воспроизводит желаемый эффект.
Модель теперь поддерживает тайский, индонезийский, португальский и вьетнамский языки. Alibaba заявляет, что среди 13 языков Fun-CosyVoice3.5 сохраняет лидирующие в отрасли показатели по бенчмаркам Word Error Rate (WER) и speaker similarity (SpkSim). Она также была оптимизирована для редких символов и сложных предложений, снизив частоту неправильного произношения для необычных символов с 15,2% до 5,3%, при этом обеспечивая более стабильную производительность при работе с длинными текстами.
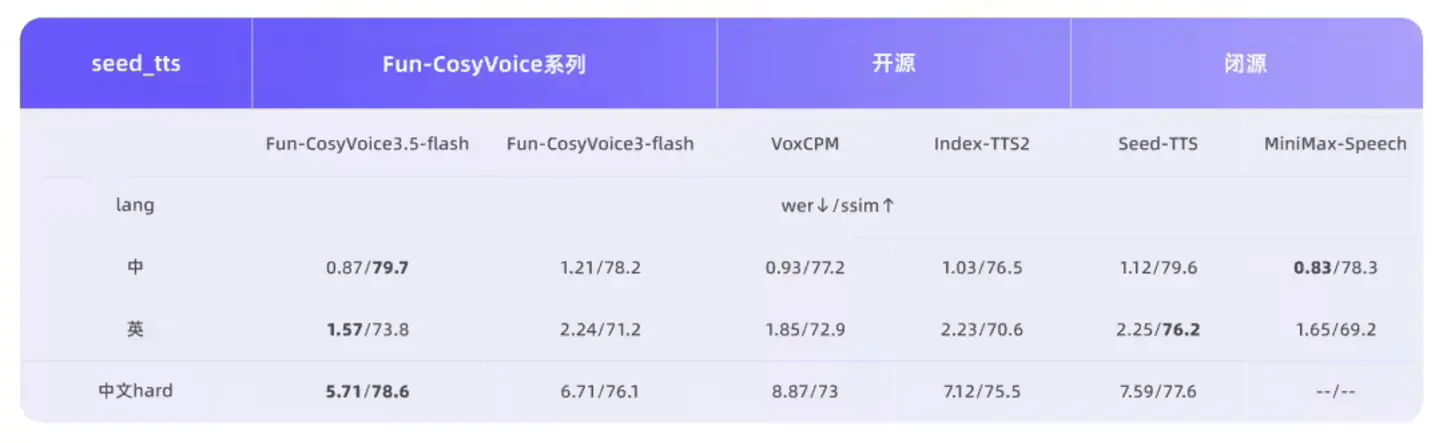
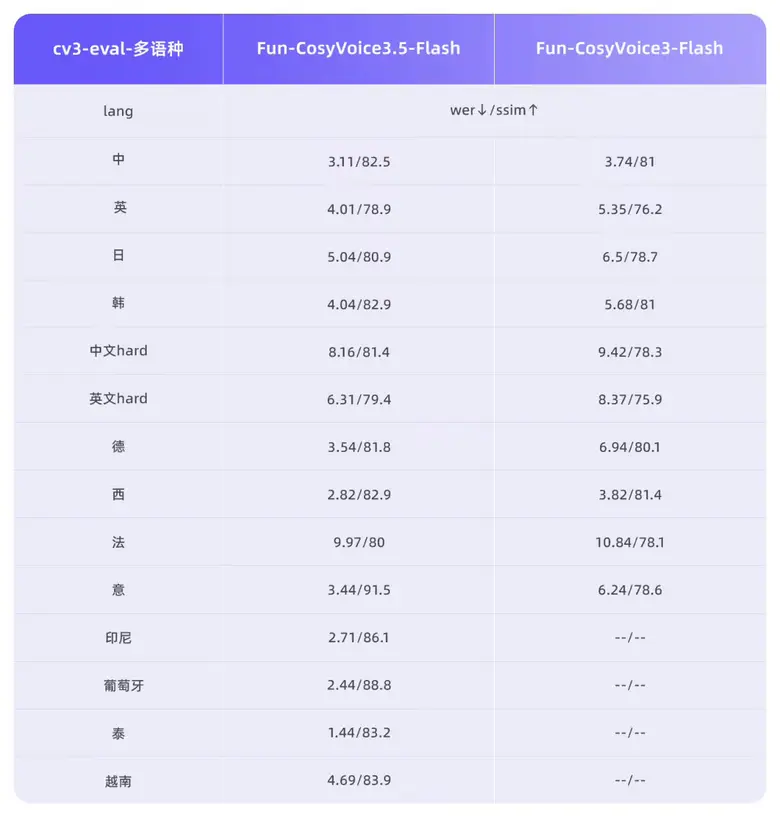
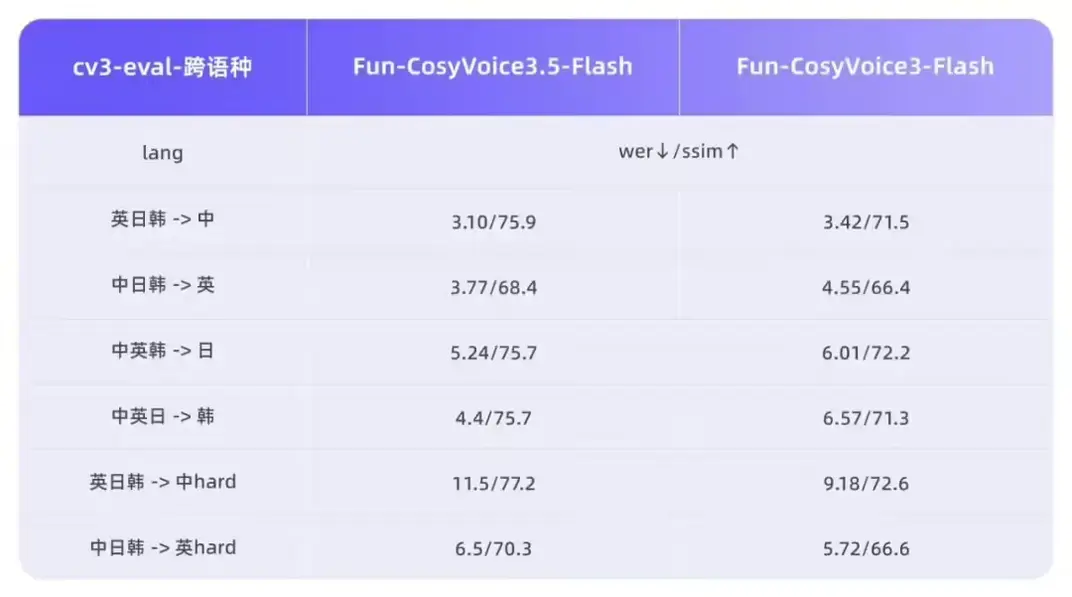
Благодаря тонкой настройке на основе обучения с подкреплением модель улучшает общую естественность и экспрессивное наслоение. Что касается производительности, частота кадров токенизатора была снижена вдвое, а задержка первого пакета уменьшена на 35%, что обеспечивает более быстрые ответы и более плавный опыт в сценариях взаимодействия в реальном времени.
Тем временем Fun-AudioGen-VD позволяет пользователям генерировать не только голоса, но и полные звуковые сцены на основе описаний на естественном языке, интегрируя персонажа и окружение в единый вывод.
Модель поддерживает детальный контроль над:
- Базовыми атрибутами: пол, возраст, акцент, высота тона, скорость речи
- Качествами тембра: хриплый, яркий, глубокий, притягательный
- Эмоциями: гнев, грусть, возбуждение, решимость
- Симуляцией ролей: агент службы поддержки, ветеран, ребенок, ИИ-помощник, диктор
- Сложными психологическими состояниями: нюансированные выражения, такие как «спокойный на поверхности, но дрожащий внутри»
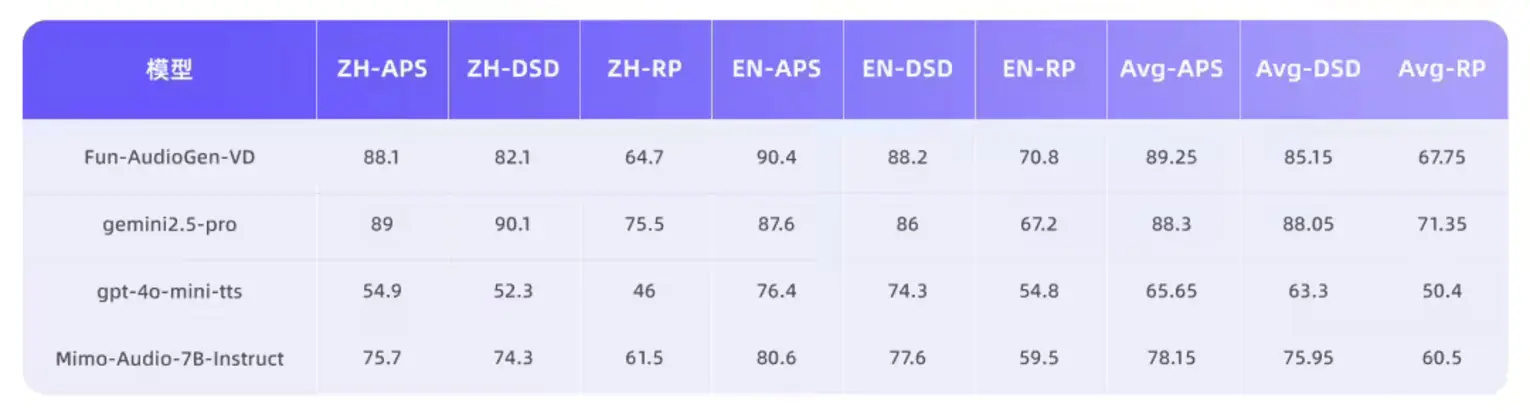
Помимо генерации голоса, Fun-AudioGen-VD может создавать иммерсивные звуковые среды, включая наложенный фоновый шум (городские улицы, кафе, поля сражений), эффекты пространственной реверберации (соборы, металлические камеры, подводная акустика), аудиофильтры в стиле устройств (винтажное радио, рация, дыхательная маска) и динамические взаимодействия с окружающей средой, такие как колеблющийся шум ветра или смещающиеся отголоски.
В совокупности эти две модели сигнализируют о продолжающихся усилиях Alibaba в области управляемой, высокоточной генерации речи и аудио, расширяя границы голосового взаимодействия на базе ИИ и создания иммерсивных медиа.
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Pandaily



