
Индийская лаборатория искусственного интеллекта Sarvam во вторник представила новое поколение больших языковых моделей, делая ставку на то, что небольшие, эффективные модели ИИ с открытым исходным кодом смогут отвоевать долю рынка у более дорогих систем, предлагаемых значительно крупнее американскими и китайскими конкурентами.
Запуск, анонсированный на India AI Impact Summit в Нью-Дели, соответствует стремлению Нью-Дели уменьшить зависимость от иностранных платформ ИИ и адаптировать модели для местных языков и сценариев использования.
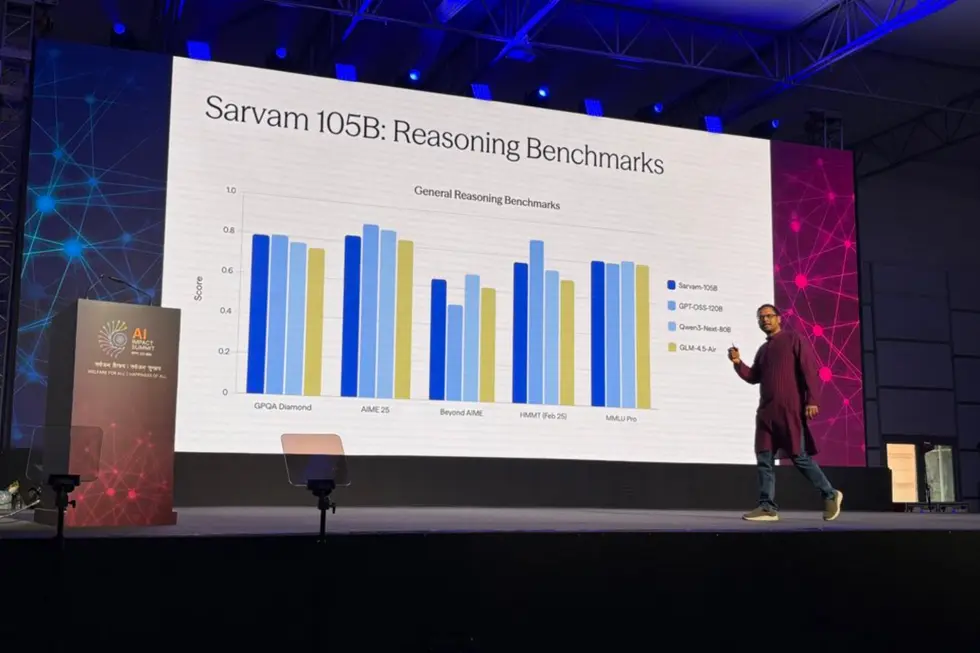
Sarvam сообщила, что новая линейка включает модели с 30 миллиардами и 105 миллиардами параметров; модель преобразования текста в речь; модель преобразования речи в текст; и модель обработки изображений для анализа документов. Это представляет собой значительное усовершенствование по сравнению с моделью Sarvam 1 с 2 миллиардами параметров, выпущенной компанией в октябре 2024 года.
30-миллиардная и 105-миллиардная модели используют архитектуру “смесь экспертов”, которая активирует лишь часть общего числа параметров за раз, значительно снижая вычислительные затраты, заявила Sarvam. 30B модель поддерживает контекстное окно в 32 000 токенов, предназначенное для разговорного использования в реальном времени, в то время как более крупная модель предлагает окно в 128 000 токенов для более сложных, многоэтапных задач рассуждения.
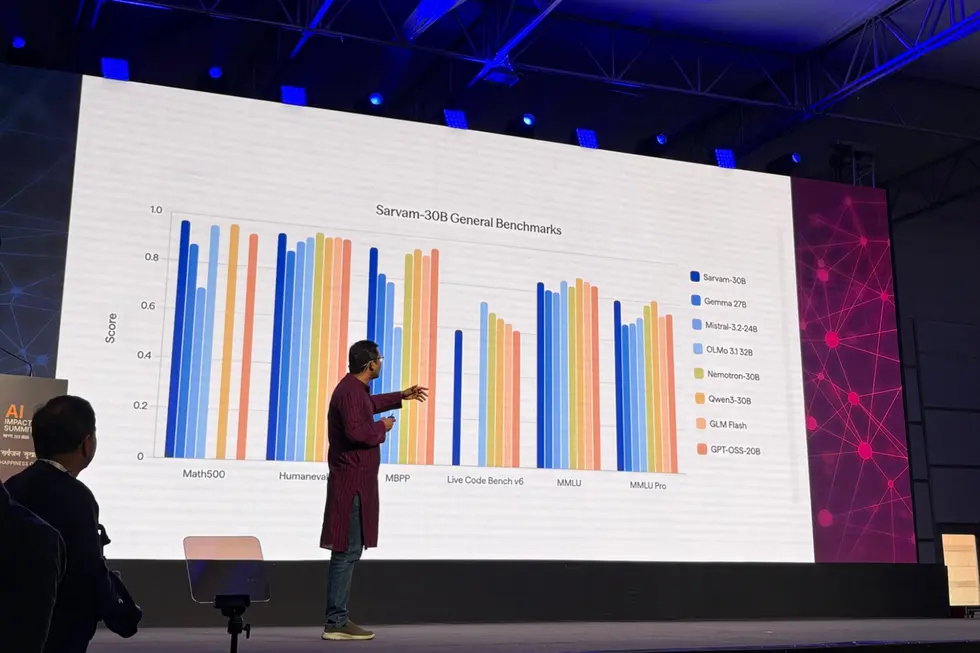
Sarvam заявила, что новые модели ИИ были обучены с нуля, а не доработаны на основе существующих систем с открытым исходным кодом. 30B модель была предварительно обучена примерно на 16 триллионах токенов текста, в то время как 105B модель была обучена на триллионах токенов, охватывающих несколько индийских языков.
Модели разработаны для поддержки приложений реального времени, включая голосовых помощников и чат-системы на индийских языках, сообщил стартап.
Стартап сообщил, что модели были обучены с использованием вычислительных ресурсов, предоставленных в рамках поддерживаемой правительством Индии программы IndiaAI Mission, при поддержке инфраструктуры оператора дата-центров Yotta и технической поддержке Nvidia.
Руководители Sarvam заявили, что компания планирует применять взвешенный подход к масштабированию своих моделей, фокусируясь на реальных приложениях, а не на сырой мощности.
«Мы хотим быть внимательными к тому, как мы осуществляем масштабирование», — сказал соучредитель Sarvam Пратьюш Кумар на презентации. «Мы не хотим масштабироваться бездумно. Мы хотим понять задачи, которые действительно важны в масштабе, и создавать решения для них».
Sarvam заявила, что планирует выпустить 30B и 105B модели с открытым исходным кодом, хотя и не уточнила, будут ли также обнародованы обучающие данные или полный код обучения.
Компания также представила планы по созданию специализированных систем ИИ, включая модели, ориентированные на программирование, и корпоративные инструменты под продуктом под названием Sarvam for Work, а также платформу разговорных ИИ-агентов Samvaad.
Основанная в 2023 году, Sarvam привлекла более 50 миллионов долларов финансирования и среди своих инвесторов называет Lightspeed Venture Partners, Khosla Ventures и Peak XV Partners (ранее Sequoia Capital India).
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Jagmeet Singh



